rozdzial 5 1/2
07 września 2019, 22:16
Rozdział 5 Test z klapkami na oczach
W TYM ROZDZIALE Dynamiczne testowanie metodami czarnej skrzynki: testowanie z zawiązanymi oczami Test „pozytywny” i test „negatywny” Metoda klas równoważności Testowanie danych Testowanie zmian stanów Inne techniki czarnej skrzynki
OK, bierzmy się do roboty! W tym rozdziale zapoznamy się z tym, co większość ludzi rozumie pod pojęciem „testowanie oprogramowania”. Czas splunąć w garści, zasiąść przed komputerem i zacząć szukać błędów.
Dla początkującego testera może to być pierwszym zadaniem. W czasie wywiadu z kandydatami na stanowisko testera, na pewno padnie pytanie, jak zabrać się za testowanie nowego programu albo nowej funkcji.
Łatwo jest ruszyć na oślep, zacząć bębnić w klawiaturę i mieć nadzieję, że uda się coś rozwalić. Takie podejście może zadziałać – przez jakiś czas. Jeśli program nie jest jeszcze gotowy, nietrudno mieć szczęście i szybko znaleźć kilka błędów. Niestety, te łatwe zdobycze szybko znikną i trzeba będzie podejść do zadania w sposób bardziej ustrukturalizoany i celowy, żeby nadal znajdować błędy i zostać testerem na wysokim poziomie.
W tym rozdziale opisane są najpowszechniejsze i najbardziej wydajne techniki testowania oprogramowania. Nie ma znaczenia, jaki rodzaj programu się testuje – te same techniki będą skuteczne zarówno dla wykonanego na zamówienie firmy pakietu do prowadzenia rachunkowósci, jak i dla oprogramowania w automatyzacji przemysłowej, jak i dla przeznaczonej na masowy rynek gry komputerowej.
Nie trzeba być programistą aby posługiwać się tymi technikami. Nawiązują one wprawdzie do podstawowych pojęć programowania, ale nie trzeba samemu pisać kodu, aby je stosować. Dla niektórych z opisanych tu tecknik podane są pewne szczegóły dla wyjaśnienia, na czym polega ich skuteczność, ale przykłady kody źródłowego są krótkie i napisane w BASIC-u aby łatwo zilustrować o co chodzi. Ci czytelnicy, którzy są programistami i chcą poznać więcej technik dających się zastosować w testowaniu na niskim poziomie, znajdą – po przeczytaniu tego rozdziału – więcej tematów dla siebie w rozdziałach 6-ym „Analiza kodu” i 7-ym „Testowanie oprogramowania pod rentgenem”.
W tym rozdziale omówione są następujące tematy:
31.Co to jest dynamiczne testowanie metodami czarnej skrzynki? 32.Jak zmniejszyc ilość zadań testowych przy pomocy podziału na klasy równoważności 33.Jak zidentyfikować kłopotliwe warunki graniczne 34.Wartości danych, które skutecznie wywołują awarie 35.Jak testować stany i zmiany stanów oprogramowania 36.Jak posługiwać się powtarzaniem, stresem i wysokim obciążeniem aby lokalizować błędy 37.Kilka miejsc gdzie błędy lubia się ukrywać Dynamiczne testowanie metodami czarnej skrzynki: testowanie z zawiązanymi oczami
Testowanie oprogramowania kiedy nie ma się wglądu w szczegóły kodu programu nazywane jest dynamicznym testowaniem metodami czarnej skrzynki. „Dynamicznym”, ponieważ program jest wykonywany – tester poługuje się nim w podobny sposób jak zwykły użytkownik. „Czarnej skrzynki”, bo testowania dokonuje się nie wiedząc dokładnie, jak program działa – jakby z zawiązanymi oczami. Wprowadza się dane wejściowe, otrzymuje dane wyjściowe i sprawdza wyniki. Inną często stosowana nazwą na dynamiczne testowanie metodą czarnej skrzynki to „testowanie behawioralne” – bada się bowiem zachowanie programu, kiedy się nim posługiwać.
Aby móc to robić skutecznie, trzeba orientować się, co program właściwie ma wykonywać – ta informacja powinna znajdować się w specyfikacji wymagań albo w dokumentacji produktu. Nie musi się wiedzieć, co się dzieje wewnątrz „skrzynki” – wystarczy wiedzieć, że dane wejściowe A mają spowodować dane wyjściowe B, zaś dane wejściowe C – dane wyjściowe D. Dobra specyfikacja produktu powinna zawierać te informacje.
Jak się już wie co wchodzi, a co powinno wychodzić z programu, można przystąpić do konstruowania zadań testowych. Zadania testowe to lista danych wejściowych, które się zastosuje i czynności, które się wykona w czasie testowania1. Rysunek 5.1 przedstawia kilka przykładów zadań testowych, które można użyć przy testowaniu dodawania w Kalkulatorze Windows.
Zadania testowe dla dodawania dla Kalkulatora Windows 0+0 powinno dać 0 0+1 powinno dać 1 254+1 powinno dać 255 255+1 powinno dać 256 256+1 powinno dać 257 1022+1 powinno dać 1023 1023+1 powinno dać 1024 1024+1 powinno dać 1025 … …
Rysunek 5.1 Zadania testowe pokazują różne dane wejściowe i czynności w trakcie testowania programu.

Wybór zadań testowych to bezwzględnie najważniejsze zadanie testera. Nieprawidłowy dobór może spowodować, że przetestuje się za dużo, za mało, albo po prostu nie to co trzeba. Te „czary” polegają na tym, by mądrze wziąć pod uwagę stopień ryzyka i umiejętnie zredukować nieskończoną ilość możliwych zadań testowych do ilości, którą rzeczywiście daje się użyć.
Pozostała część tego rozdziału – a także znaczna część reszty książki – nauczy nas sposobów strategicznego dobierania dobrych zadań testowych. Rozdział 17-y „Jak pisać zadania testowe i rejestrować ich wyniki” opisuje konkretne sposoby zapisywania i zarządzania zadaniami testowymi.
Testowanie eksploracyjne kiedy brakuje specyfikacji
Testując oprogramowanie wytwarzane w ramach profesjonalnego, dojrzałego procesu wytwarzania, ma się do dyspozycji szczegółową specyfikację. Testując programy wytwarzane metodą skokową albo prób i błędów, zwykle nie ma się żadnej specyfikacji. To marna sytuacja dla testera, ale jest szansa na działające rozwiązanie, jeśli posłużyć się tak zwanym testowaniem eksploracyjnym.
Program traktuje się jak specyfikację i metodycznie „eksploruje” wszystkie jego funkcje jedna po drugiej. Zbiera się notatki na temat działania programu, sprządza mapę jego funkcji i stosuje niektóre z technik czarnej skrzynki opisanych w rozdziale 3-im „Test oprogramowania w rzeczywistości”. Program analizuje się tak jakby rzeczywiście był specyfikacją, po czym stosuje się opisane w niniejszym rozdziale techniki testowania dynamicznego metodami czarnej skrzynki.
Nie da się tą metodą przetestować programu równie gruntownie jak wtedy, kiedy specyfikacja jest dostępna – nie uda się na przykład odnaleźć funkcji brakujących. Niemniej, da się program systematycznie przetestować. Jeśli uda się znaleźć troche błędów, to już w tej sytuacji sukces. Test „pozytywny” i test „negatywny”
Istnieją dwa podstawowe podejścia do testowania programów: testowanie pozytywne i testowanie negatywne. Testy pozytywne kontrolują jedynie, że oprogramowanie funkcjonuje poprawnie na swego rodzaju minimalnym poziomie. Nie testuje się granic zbyt daleko, nie szuka się sposobów wywołania awarii za wszelką cenę. Postępuje się delikatnie, w rękawiczkach, stosując tylko najprostsze i najbardziej oczywiste zadania testowe.
Jeśli jednak celem ma być znajdowanie błędów, po co w ogóle robić testy pozytywne? Czyż nie chcemy za wszelką cenę znajdować błędów, stosując najbardziej demomniczne zadania testowe? Tak, ale nie od razu.
Wyobraźmy sobie analogię z testowaniem nowego modelu samochodu (rysunek 5.2). Testując pierwszy prototyp, który dopiero co opuścił linie montażową i nigdy jeszcze nie jeździł, nie będzie się go od razu prowadzić na pełen gaz tak ostro, jak tylko się da. Kierowca testowy przypuszczalnie szybko rozbiłby próbny samochód. W nowym samochodzie pełno błędów ujawni się nawet przy powolnjej jeździe w normalnych warunkach. Może opony maja złą średnicę albo hamulce są niesprawne, albo silnik zbyt szybko wchodzi na wysokie obroty. Należy znaleźć te usterki i naprawić je, zanim przyciśnie się gaz do końca na torze próbnym1.
1 Autor stosuje – jak wynika z podanego przykładu – termin testowanie negatywne częściowo w tym znaczeniu, które zwykle określa się jako testowanie wydajności albo testowanie pod obciążeniem. Zaś testowanie negatywne to wedle powszechnej praktyki określenie testowania zadaniami, gdzie dane wejściowe są niedozwolone, albo odwrotne do wymagań opisanych w specyfikacji (przyp. tłumacza).
Rysunek 5.2 Należy najpierw posłużyć się testowaniem pozytywnym zanim przejdzie się do testowania negatywnego.
Projektując i wykonując zadania testowe, zawsze najpierw należy wykonywać testy pozytywne. Trzeba najpierw sprawdzić, czy program działa w normalny sposób, zanim zacznie się testować „z grubej rury”. Może to zdziwić, ale wielką ilość błędów znajduje się używając programu w najnormalniejszy sposób.
Kiedy jest się już przekonanym, że oprogramowanie działa zgodnie ze specyfikacją w zwykłych warunkach, czas zastosować podstępne, złe, przebiegłe zadania, które mają na celu zmusić nawet dobrze ukryte błędy do ujawnienia się. Projektowanie i wykonywanie zadań testowych, których głównym celem jest złamanie programu nazywane jest testowaniem negatywnym albo wymuszniem awarii. Jak zobaczymy w dalszej części tego rozdziału, testy negatywne nie zawsze muszą wyglądać „groźnie”. Często wyglądają jak testy pozytywne, ale są wybrane strategicznie w punktach, gdzie często kryją się typowe słabości oprogramowania.
Komunikaty o awarii: test pozytywny czy test negatywny?
Często spotykaną grupą zadań testowych są zadanie mające na celu wymuszenie komunikatów o awariach programu. Znamy je dobrze – jak ten który się pojawia jeśli polecić zapisanie pliku na dyskietce nie włożywszy dyskietki do stacji dysków. Tego rodzaju zadania znajdują się na samej granicy między testami pozytywnymi i negatywnymi. Specyfikacja zapewne określa, że pewna sytuacja powinna spowodować wyświetlenie komunikatu o awarii. To jest typowe testowanie pozytywne. Z drugiej strony, wymuszając zaistnienie awaryjnej sytuacji, mamy do czynienia z czymś podobnym do testowania negatywnego. W gruncie rzeczy, test komunikatów o awariach jest zapewne jednym i drugim zarazem.
Nie warto trapić się ścisłą definicją. Ważne jest natomiast, aby wymusić pojawienie się wszystkich komunikatów o awariach, które przewidziała specyfikacja wymagań, ale też wynaleźć takie sytuacje awaryjne, których specyfikacja nie przewiduje. Prawdopodobnie znajdzie się błędy w obu wypadkach. Metoda klas równoważności
Wybór zadań testowych jest najważniejszym zadaniem testera, a metoda podziału na klasy równoważności jest najbardziej podstawową techniką stosowaną w tym celu. Podział na klasy równoważności jest procesem metodycznego zmniejszenia olbrzymiego (często nieskończonego) zbioru możliwych zadań testowych do zbioru znacznie mniejszego, ale nadal dostatecznie skutecznego.
W przykładzie z testowaniem Kalkulatora Windowsów z rozdziału 3-ego, nie dało się przetestować wszystkich możliwych kombinacji dodawania dwóch liczb. Podział na klasy równoważności jest sposobem, żeby wybrać wartości istotne i odrzucić zbędne.
Na przykład, nawet nic nie wiedząc o podziale na klasy równoważności, czy można przypuszczać, że przetestowawszy 1+1, 1+2, 1+3 i 1+4 warto jeszcze testować 1+5 i 1+6? Czy też dałoby się bezpiecznie założyć, że będą działać poprawnie?
A co można przypuszczać o 1+99999999999999999999999999999999 (największa liczba jaką daje się wprowadzic do kalkulatora)? Może to zadanie testowe jest trochę inne od pozostałych, może należy jakby do innej klasy, do innej klasy równoważności? Stanąwszy przed koniecznością wyboru, czy wybrałoby się raczej to zadanie, czy na przykład 1+13?
Patrzcie, już zaczynamy myśleć jak zawodowi testerzy oprogramowania!
Klasa równoważności to zbiór zadań testowych które testują to samo albo ujawniają ten sam błąd.
Jaka jest różnica między 1+99999999999999999999999999999999 a 1+13? Jeśli chodzi o 1+13, to wygląda ono na zwykłe, proste dodawanie, takie samo jak na przykład 1+5 albo 1+392. Natomiast 1+99999999999999999999999999999999 jest daleko, gdzieś na skraju. Jeśli wziąć największa możliwą liczbę i dodać do niej 1, może zdarzyć się coś niedobrego – może odkryje się błąd? Ten wypadek skrajny jest osobną klasą równoważności1, inną niż klasa „zwyczajnych” liczb.
Identyfikując klasy równoważności, warto wziąć pod uwagę sposoby, jak pogrupować razem podobne dane wejściowe, podobne dane wyjściowe i podobne działania programu. Te grupy mogą być stosownymi klasami równoważności.
Przypatrzmy się kilku przykładom.
38.Przy dodawaniu dwóch liczb, wydawała się istnieć wyraźna różnica między przetestowaniem 1+13 a 1+99999999999999999999999999999999. Nazwijmy to intuicją, ale pierwsze wydaje się zwykłym dodawaniem, drugie wydaje się ryzykowne. Ta intuicja jest trafna. Program musi wykonywac dodawanie jednego do wartości maksymalnej w zupełnie inny sposób niż dodawanie dwóch małych liczb. Te dwa wypadki, ponieważ program przypuszczalnie działa dla nich zupełnie inaczej, należą do dwóch różnych klas równoważności.
Jeśli zna się trochę programowanie, przychodzi do głowy jeszcze klika innych „specjalnych” liczb na których program będzie wykonywał operacje w specjalny sposób. Jeśli nie zna się programowania, uszy do góry – można opanować opisane techniki i stosować je bez konieczności rozumienia szczegółów kodu. 39.Rysunek 5.3 przedstawia menu Edycji z Kalkulatora z rozwiniętymi poleceniami Kopiuj i Wklej. Każdą z tych funkcji można wykonac na pięć różnych sposobów. Aby skopiować, można kliknąć na pozycję menu, nacisnąć „c” albo „C”, nacisnąć kombinację Ctrl+c albo Ctrl+Shif+c. Każde z tych poleceń skopiuje aktualną liczbę do Schowka – wykona tę samą procedurę i osiągnie ten sam wynik.
Rysunek 5.3 Różne sposoby przywołania funkcji kopiowania dają ten sam wynik.

Jeśli ma się przetestować funkcję kopiowania, można podzielić tych pięć różnych ścieżek na trzy grupy (klasy równoważności): kliknięcie na polecenie z menu, napisanie „c” albo naciśnięcie Ctrl+c. Jeśli wzrasta nasze zaufanie do jakości testowanego oprogramowania i weiemy, że jak dotąd funkcja kopiowania działała dobrze niezależnie od sposobu, w jaki się ją przywołało, można się zdecydować na dalsze ograniczenie ilości klas równoważności, nawet do jednej tylko, np. Ctrl+c. 40.W trzecim przykładzie, przyjrzyjmy się możliwym sposobom wprowadzenia nazwy pliku do standardowego okna dialogowego „Zapisz jako” (rysunek 5.4).
Rysunek 5.4 Pole do wprowadzenia nazwy pliku w oknie dialogowym „Zapisz jako” ilustruje kilka różnych możliwości podziału na klasy równoważności.
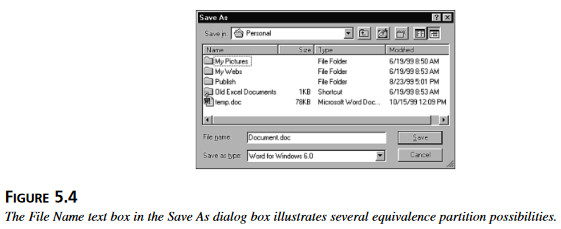
Nazwa pliku w Winodows może zawierać dowolne znaki z wyjątkiem \ / : * ? „ < > i | . Nazwy plików mogą składać się od jednego do 255 znaków. Konstruując zadania testowe dla nazw plików, można na przykład wybrać osobne klasy równoważności dla dozwolonych i niedozwolonych znaków, nazw o dozwolonej ilości znaków, nazw zbyt krótkich i nazw zbyt długich.
Pamiętajmy, że celem podziału na klasy równoważności jest zredukowanie zbioru możliwych zadań testowych do małego i dającego się zastosować w praktyce, ale wciąż jeszcze dostatecznie dobrze testującego oprogramowanie. Podejmując decyzję, że nie będzie się testować wszystkiego, ponosi się ryzyko, trzeba więc dobrze się zastanowić, jak wybrać klasy równoważności, żeby poziom ryzyka mieć pod kontrolą.
Jeśli posunąć się za daleko w redukcji ilości klas równoważności po to, aby zmniejszyc ilość zadań testowych, ryzykuje się wyeliminowanie testów które mogłyby ujawnic błędy. Początkującym testerom można zalecić, żeby poddali wybrane przez siebie klasy równoważności ocenie kogoś bardziej doświadczonego.
Na zakończenie wykładu o klasach równoważności warto dodać, że podział na klasy nie jest ścisły, jest subiektywny. Nie jest nauką, lecz raczej sztuką. Dwaj testerzy testujący ten sam program mogą zaproponować dwa różne zestawy klas równoważności. Jest to do przyjęcia pod warunkiem, że wybrane klasy zostały poddane przeglądowi i że zdają się zapewniać dostateczne pokrycie testowanego oprogramowania. Testowanie danych
Najprostszym sposobem wyobrażenia sobie programu komputeroego jest podzielic go na dwie części: dane oraz program. Danymi stają się dane wejściowe z klawiatury, kliknięcia myszą, pliki z dysku, wydruki itd. Program to przepływ sterowania, transakcje, logika i wyliczenia numeryczne. Często dzieli się test oprogramowania na analogiczne dwie części.
Wykonując testy na danych programu, kontroluje się informacje wprowadzane przez użytkownika, uzyskiwane wyniki, a także pośrednie wyniki ukryte w programie.
Kilka przykładów danych: 41.Wyrazy napisane przez użytkowanika w programie do przetwarzania tekstu 42.Liczby wprowadzone w arkusz kalkulacyjny 43.Ilość pozostających jeszcze do dyspozycji strzałów w grze komputerowej 44.Obraz wydrukowany przez oprogramowanie do przetwarzania fotografii 45.Kopie zapasowe plików na dyskietce 46.Dane przsyłane za pośrednictwem modemu przez linie telefoniczne
Ilość danych przetwarzanych nawet przez najprostszy program może być ogromna. Przypomnijmy sobie wszystkie możliwe kombinacje dodawania na zwykłym kalkulatorze. Wyobraźmy sobie teraz program do przetwarzania tekstu, system naprowadzający pocisków rakietowych albo program do przetwarzania danych na giełdzie. Sztuczka (jeśli można tak to nbazwać) jak uczynić to możliwym do przetestowania polega na tym, aby inteligentnie zmniejszyc ilość klas równoważności posiłkując się kilkoma podstawowymi zasadami: warunków granicznych, warunków granicznych dla podklas, pustych zbiorów danych i niedozwolonych danych1.
1 Uwaga tłumacza: Cały ten rozdział należałoby raczej zatytułować “Jak stosować klasy równoważności w praktyce”. Tytuł “Testowanie danych” wprowadza w błąd, ponieważ kłóci się z powszechnie przyjętymi definicjami “testowania danych”. Statyczne testowanie danych polega na poszukiwaniu w kodzie źródłowym błędów typu użycie zmiennej przed przydzieleniem jej wartości, użycie zmiennej poza zakresem jej definicji itp. Dynamiczne testowanie danych polega na oszacowaniu pokrycia testowego np. wszystkich ścieżek od definicji do pierwszego użycia wszysktkich zmiennych programu. Te
Warunki graniczne
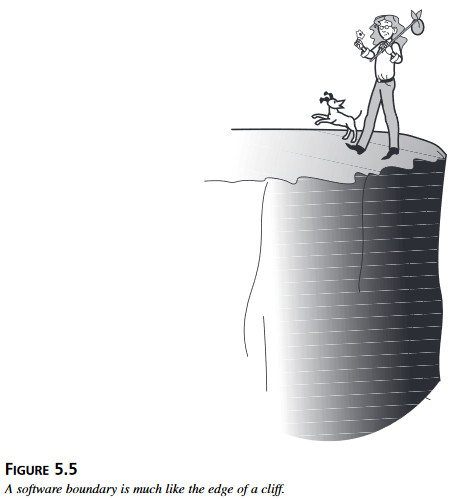
Najlepszym sposobem opisania testowania warunków granicznych jest rysunek 5.5. Jeśli daje się bezpiecznie i pewnie przejść brzegiem urwiska i nie spaść, to prawie na pewno daje się też iść środkiem pola. Jeśli oprogramowanie działa poprawnie dla wartości skrajnych, to prawie na pewno będzie też działać dobrze w normalnych warunkach.
Warunki graniczne są szczególnych wypadkiem, ponieważ programownaie jest ze swojej natury narażone na problemy związane z definicją warunków brzegowych2. Oprogramowanie jest binarne – coś jest albo prawdą, albo nie. Jeśli jakaś operacja może być wykonywana na przedziale wartości, to istnieje ryzyko, że nawet jeśli programista nie zrobił błędu dla wartości ze środka przedziału, to popełnił błąd właśnie na krawędzi. Wydruk nr 5.1 pokazuje, jak problem warunków brzegowych łatwo wciska się do prościutkiego programu.
Wydruk 5.1 Prosty program w BASIC-u, demostrujący błąd warunków brzegowych.
1. Rem Stwórz 10-elementowy wektor całkowitoliczbowy 2. Rem Przydziel każdemu elementowi wartośc –1 3. Dim data (10) As Integer 4. Dim i As Integer 5. For i=1 To 10 6. data(i)=-1 7. Next i 8. End
Rysunek 5.5 Granica w oprogramowaniu przypomina krawędź urwiska.
metody są poza zakresem niniejszej książki (przyp. tłumacza).
2 Słów “brzegowe”, “graniczne” i “skrajne” używa się tutaj zupełnie zamiennie (przyp. tłumacza).
Ten fragment kodu ma stworzyć 10-elementowy wektor i nadać każdemu elementowi wektoru wartość –1. Wydaje się to bardzo proste. Wektor na 10 liczb całkowitych i licznik (i) zostają stworzone. Pętla For jest wykonywana od 1 do 10, i każdy element wektoru otrzymuje wartość –1. Gdzie problem z wartością graniczną?
W programach w BASIC-u, kiedy stwarza się wektor o podanym zasięgu – w tym wypadku, Dim data (10) as Integer – pierwszy element wektoru orzymuje numer 0, a nie 1. Podany program w rzeczywistości stwarza wektor mający 11 elementów, od data(0) do data(10). Program wykonuje pętlę od 1 do 10 i nadaje tym elementom wektoru wartość –1, ale ponieważ pierwszy element to data(0), nie otrzymuje on żadnej wartości. Kiedy program skończy przebieg, wartości wektoru są następujące: data(0)=0 data(6)=-1 data(1)=-1 data(7)=-1 data(2)=-1 data(8)=-1 data(3)=-1 data(9)=-1 data(4)=-1 data(10)=-1 data(5)=-1 Zwróćmy uwagę, że wartość elementu data(0) nie jest –1, lecz 0. Gdyby programista później zapomniał o tym, albo inny programista nie zdawał sobie sprawy, jak ten wektor został zainincjowany, mógłby użyć pierwszego elementu wektoru, data(0), sądząc że ma on wartośc –1. Tego typu problemy są bardzo powszechne i we większych, złożonych systemach często powodują przykre, trudne do zlokalizowania błędy1.
Rodzaje warunków granicznych
Czas już aby naprawdę uruchomić szare komórki i zastanowić się, co właściwie stanowi granicę. Początkujący testerzy nie zawsze zdaja sobie sprawę, jak wiele różnych granic moża wyznaczyć na jednym zbiorze danych. Często mamy do czynienia z kilkoma granicami rzucającyjmi się w oczy, ale jeśli poszperać głębiej, znajdzie się liczne dalsze granice bardziej ukryte, słabo zauważalne i narażone na trudne do wykrycia błędy.
Warunki graniczne to sytuacje powstające na krawędziach planowanych operacyjnych ograniczeń oprogramowania.
Zetknąwszy się z zagadnieniem w dziedzinie testowania oprogramowania, które wymaga zidentyfikowania granic, należy wziąć pod uwagę następujące typy danych: numeryczne szybkość znaki położenie pozycja wielkość ilość
Następnie trzeba uwzględnić następujące atrybuty powyższych typów: pierwszy/ostatni minimum/maksimum początek/koniec ponad/poniżej pusty/pełny najkrótszy/najdłuższy najwolniejszy/najszybszy najbliższy/najdalszy (w czasie) największy/najmniejszy najwyższy/najniższy następny/najdalszy (w kolejności)
Nie są to listy ostateczne. Zawierają większość możliwych warunków brzegowych, ale każde oprogramowanie jest inne i mogą w nim znajdować się zupełnie inne typy danych ze swoistymi warunkami granicznymi.
Mając możliwośc wyboru wartości, której użyje się do przetestowania danej klasy równoważności, zaleca się użycie wartości leżących na granicy klasy (przedziału wartości).
Testowanie w pobliżu granic
Nauczyliśmy się jak dotąd, że w celu ograniczenia ilości zadań testowych, należy podzielić zbiory danych, na których dokonuje operacji testowane oprogramowanie, na mniejsze zbiory zwane klasami równoważności. Ponieważ błędy oprogramowania często występują na granicach przedziałów wartości, wybierając dane testowe należące do klasy równoważności, warto wybierać wartości leżące na granicach – w ten sposób zwykle znajduje się więcej błędów.
Jednak samo testowanie wyłącznie na granicy przedziałów zwykle nie wystarcza. Najlepiej jest testować po obu stronach granicy1.
(przyp. tłumacza).1 Szegółowa analiza tych zagadnień należy to tak zwanego testowania domen (nie ma nic wspólnego z domenami Internetowymi). Te zagadnienia opisane są obszernie w kilku pozycjach z listy referencji
Najwięcej błędów znajduje się, stworzywszy dwie klasy równoważności (wokół każdej granicy). Do pierwszej z nich zaliczy się wartości, które leżą bezpiecznie we wnętrzu przedziału, stanowiącego klasę równoważności. Do drugiej klasy zaliczy się wartości niedozwolone, leżące poza testową klasą – wartości co do których oczekuje się, że mogą wywołać jakąś awarię.
Tesutując warunki graniczne, należy zawsze przetestować dozwoloną wartość tuż przy samej wartości granicznej, wartość graniczną oraz wartość niedozwoloną położoną jak najbliżej granicy.
Testowanie poza granicami jest z reguły łatwo uzyskać dodając jeden albo inną małą wielkośc, do górnej granicy, a odejmując jeden albo inną małą wielkość, od dolnej granicy2. Na przykład: 47.Pierwszy-1 / ostatni+1 48.Start-1 / koniec+1 49.Mniej niż pusty / więcej niż pełny 50.Jeszcze wolniejszy / jeszcze szybszy 51.Największy+1 / najmniejszy-1 52.Minimum-1 / maksimum+1 53.Tuż ponad / tuż pod 54.Jeszcze krótszy / jeszcze dłuższy 55.Jeszcze wcześniej / jeszcze później 56.Najwyższy+1 / najniższy-1
Przypatrzmy się kilku przykładom, które ułatwią zrozumienie, jak mysleć na temat możliwych granic i ich testów: 57.Jeśli pole tekstowe dopuszcza wprowadzenie od 1 do 255 znaków, należy wprowadzić 1 i 255 znaków, jako wartości z klasy wartości dozwolonych. Następnie należy wprowadzić 0 i 256 znaków jako wartości z klasy wartości niedozwolonych. 58.Jeśli program czyta i pisze dane na dyskietce, należy spróbować zapisać plik bardzo mały, najlepiej z jedną tylko pozycją, a następnie plik bardzo duży – dokładnie limit pojemności dyskietki. Należy też spróbować zapisać plik pusty i plik większy niż pojemność dyskietki.
2 Dotyczy to oczywiście zmiennych całkowitych. Zmienne rzeczywiste (zmiennoprzecinkowe) wymagają bardziej precyzyjnych manewrów numerycznych (przyp. tłumacza).
59.Jeśli program pozwala na wydruk wielu stron na jednej stronie, należy wydrukować jedną stronę i maksymalną ilość stron, na którą program zezwala, a następnie spróbować wydrukować zero stron i większą ilość niż maksymalna dozwolona przez program. 60.Program ma pole do wprowadzania 5-cyfrowego kodu pocztowego. Należy wtedy wypróbować 00-000, najprostsze i najmniejsze, a także wartość największą 99-999. Następnie należy wypróbować np. 00-00 i 100-000. 61.Testując symulator lotów, należy spróbować lecieć dokładnie na poziomie ziemi oraz na maksymalnej dozwolonej dla samoloty wysokości. Należy też spróbować lotu poniżej poziomu gruntu, poniżej poziomu wody, a także spróbowac wylecieć w kosmos.
Ponieważ nie da się przetestować wszystkiego, przeprowadzenie podziału na klasy równoważności i uwzględnienie warunków brzegowych, tak jak w powyższych przykładach, pozwoli storzyć zadania testowe dla wartości krytycznych. Jest to najskuteczniejsza metoda zmniejszenia ilości testowania do wykonania.
Jest niezmiernie ważne, żeby nauczyć się wciąż poszukiwać warunków brzegowych w każdym oprogramowaniu, z którym ma się do czynienia. Im więcej będzie się szukać, tym więcej odkryje się warunków granicznych, a tym samym i znajdzie błędów.
Wewnętrzne warunki graniczne
Normalne warunki graniczne wyżej opisane jest bardzo łatwo znaleźć. Są opisane w specyfikacjach i rzucają się w oczy, kiedy używa się programu. Niektóre wewnętrzne granice nie są widoczne dla użytkownika, ale powinien je skontrolować tester oprogramowania. Nazywa się je wewnętrznymi warunkami granicznymi albo warunkami granicznymi podklas.
Nie musi się być programistą ani umieć czytać kodu źródłowego, aby identyfikować te granice, ale potrzebna jest pewna ogólna orientacja w działaniu oprogramowania. Przykładami mogą być potęgi dwójki i tabela ASCII. Testowany program może mieć jeszcze inne granice wewnętrzne, warto więc porozmawiać z programistami, czy znają jeszcze jakieś inne wewnętrzne warunki graniczne, które wartoby przetestować1.
1 Przykłady opisane w książce stosują się w pierwszym rzędzie do interfejsu użytkownika dla typowych aplikacji użytkowych. Analogiczne przykłady mozna by znaleźć także dla innych typów oprogramowania, łącznie z systemami wbudowanymi, dla interfejsu komunikacyjnego itd.
Potęgi dwójki
Komputery i oprogramowanie oparte są na liczbach binarnych – bitach mogących miec wartość 0 lub 1, bajtach składających się z ośmiu bitów, słowach składających się z czterech bajtów itd. Tablea 5.1 pokazuje często używane potęgi dwójki i ich wartości.
Tabela 5.1 Wybrane wartości potęg dwójki Nazwa Wartość Bit 0 lub 1 Połówka bajtu 0-15 Bajt 0-255 Słowo 0-65 535 albo 0-4 294 967 295 Kilo 1024 Mega 1 048 576 Giga 1 073 741 824 Tera 1 099 511 627 776
Przedziały pokazane w tabeli 5.1 są listą wartości, które warto uwzględnić przy testowaniu warotści granicznych. Zwykle nie znajduje się ich definicji w specyfikacji produktu, często jednak są używane wewnętrznie przez program.
Przykłady potęg dwójki
Potęgi dwójki mają znaczenie przy testowaniu oprogramowania do realizacji protokolów komunikacyjnych. Szerokość pasma, czyli zdolność przesyłowa nośnika informacji, jest zawsze ograniczona. Zawsze jest potrzeba, żeby przesyłać informację jeszcze szybciej. Z tego powodu inżynierownie usiłują upchnąć jak najwięcej danych w każdy meldunek czy pakiet przesyłowy.
Jednym ze sposobów zwiększenia przepustowości łączy jest zagęszczenie informacji.
Załóżmy, że w protokole komunikacyjnym jest 256 poleceń. Protokół mógłby zezwalać na wysyłanie 15 najczęstszych poleceń zakodowanych w połówce bajtu. Komendy z numerami 16 – 256 trzeba by wysyłać zakodowane w cały bajt.
Użytkownik tego oprogramowania potrzebuje jedynie wiedzieć, że może wysłać 256 różnych poleceń i nie musi wiedzieć, że oprogramowaniue musi wykonywać specjalne wyliczenia na granicy półbajt/bajt.
Tworząc klasy równoważności, należy uwzględnić warunki graniczne wynikające z potęg dwójki. Jeśli, na przykład, program przyjmuje dane o wartości od jednego do 1000, należy włączyć do klasy wartosci dozwolonych 1 i 1000, może też 2 i 999. Aby pokryć testami także granice wynikające z zasady potęg dwójki, włącza się również 14, 15 i 16 na granicy pół-bajtu i 254, 255 oraz 256 na granicy bajtu.
Tabela ASCII
Innym wartym uwzględnienia warunkiem wewnętrznej granicy jest tabela znaków ASCII. Tabela 5.2. zawiera część tabeli ASCII.
Tabela 5.2 Częściowa tabela znaków ASCII
Znak Wartość ASCII Znak Wartość ASCII wartość zerowa 0 B 66 znak spacji 32 Y 89 / 47 Z 90 0 48 [ 91 1 49 ‘ 96 2 50 a 97 9 57 b 98 : 58 y 121 @ 64 z 122
A 65 { 123
Zwróćmy uwagę, że tabela 5.2 nie jest ciągłą listą. Znaki od ‘0‘ do ‘9‘ mają warotści ASCII od 48 do 57. Ukośnik, ‘/‘, wypada przed ‘0‘. Dwukropek, ‘:‘, wypada po ‘9‘. Duże litery od ‘A‘ do ‘Z‘ mają warotści od 65 do 90. Małe litery mają wartości od 97 do 122. Wszystkie te wartości mogą stanowić wewnętrzne warunki graniczne.
Testując oprogramowanie które przyjmuje tekstowe dane wejściowe albo które dokonuje konwersji plików tekstowych, warto przestudiować tabelę ASCII i wziąć pod uwagę wynikające z niej warunki graniczne przy ustalaniu klas równoważności. Na przykład testując pole do wprowadzania danych, które przyjmuje tylko znaki A – Z i a – z1, należy uwzględnić w klasie wartości niedozwolonych znaki bezpośrednio pod i bezpośrednio nad A, Z, a i z: ‘@‘, ‘[‘, ““ i ‘{‘.
ASCII i Unicode
Choć kod ASCII jest nadal bardzo popularny jako metoda kodowania znaków, stopniowo zastępuje go nowy standard zwany Unicode. Unicode został stworzony przez konsorcjum Unicode w 1991 roku aby rozwiązać problemy związane z tym, że kod ASCII nie wystarcza na wszystkie znaki istniejące we wszystkich pisanych językach.
Kod ASCII jest 8-bitowy i wystarcza wobec tego tylko na 256 różnych znaków. Unicode używa 16 bitów i wystarcza na 65536 znaków. Do dziś wykorzystano około 39000 znaków, z czego ponad 21000 przypada na znaki chińskie.
Wartość domyślna, wartość pusta, spacja, wartość zerowa, brak danych
Innym źródłem błędów jest sytuacja, kiedy program oczekuje danych wejściowych, ale użytkownik nie wprowadza niczego, jedynie na przykład naciska klawisz Enter. Ta sytuacja jest często przeoczona przy pisaniu specyfikacji wymagań i zapomniana przez programistów, ale zdarza się powszechnie podczas użytkowania programów.
Poprawnie działające oprogramowanie jest w stanie poradzić sobie z tą sytuacją. Program może posłużyć się wartością domyślną, często najniższą z przedziału dozwolonych wartości, albo wyświetlić zawiadomienie o awarii.
Okno dialogowe ustawień programu Paint w Windows (rysunek 5.6) umieszcza wartości domyślne w polach Szerokość i Wysokość. Co się stanie, jeśli użytkownik usunie te wartośći, celowo lub przez przypadek?
(przyp. tłumacza).1 Sprawa komplikuje się w wypadku języków używających znaków spoza serii A – B, na przykład polskiego. Znaki legalne dla pola tekstowego będą wtedy znajdować się rozsiane po większym przedziale wartości
Rysunek 5.6 Okno dialogowe ustawień programu Paint z wyzerowanymi polami Szerokość i Wysokość.

Najlepiej byłoby, aby program dostarczył jakieś typowe wartości domyślne, albo wyświetlił komunikat o błędzie. To właśnie robi program Paint (rysunek 5.7). Komunikat nie jest zbyt jasny, ale to odrębne zagadnienie.
Rysunek 5.7 Komunikat błędu wyświetlony jeśli nacisnęło się klawisz Enter z wyzerowanymi polami Szerokość i Wysokość.

Zawsze należy storzyć klasę równoważności dla wartości domyślnej, pustej, znaku pustego, wartości zerowej, zera albo braku danych.
Dla tych wartości warto stworzyć osobną klasę, zamiast upychać je razem z klasą wartości dozwolonych albo z klasą wartości niedozwolonych, ponieważ programy zwykle postępują z nimi w specjalny sposób. Jest prawdopodobne, że program wykonuje inną ścieżkę kiedy wprowadzi się wartość domyślną niż kiedy wprowadzi się niedozwolone wartości - 0 albo 1. Jeśli oczekuje się innego działania programu, dane te powinny mieć osobną klasę równoważności.
Dane nieprawidłowe, błędne, mylne i śmieci
Ostatnim rodzajem testowania danych jest użycie „śmieci”, danych bezużytecznych. Jest to przykład testu negatywnego. Kiedy już sprawdziło się, że program działa dla zadań testowych pozytywnych, pora sięgnąć po grubszy kaliber – prawdziwe śmieci.
Puryści mogą się spierać, że nie jest to naprawdę potrzebne, że skoro przetestowało się wszystko, co opisaliśmy dotąd, w tym dane niedozwolone, to program będzie działać poprawnie. W rzeczywistości jednak może się przydać sprawdzenie, jak program poradzi sobie z zupelnie przypadkowymi danymi.
Jeśli wziąć pod uwagę, że wiele programów sprzedaje się dziś w setkach milionów egzemplarzy, na pewno jakiś procent użytkowników posłuży się nimi nieprawidłowo. Jeśli w wyniku tego program ulegnie poważnej awarii i nastąpi utrata danych, użytkownik nie będzie obwiniać siebie samego – będzie winił oprogramowanie. Jeśli program nie robi tego, czego od niego oczekują, to jest błąd.
Tak więc możemy dobrze się zabawić podstawiając programowi dane nieprawidłowe, błędne, mylne. Jeśli program oczekuje liczb, podamy mu litery. Jeśli przyjmuje tylko liczby dodatnie, podamy mu ujemne. Jeśli działanie programu zależy od daty, sprawdzimy czy będzie działal w roku 3000-ym. Będziemy udawać, że mamy grube paluchy, naciskając po kilka klawiszy jednocześnie.
Nie ma innych zasad dla tego typu testowania – po prostu chodzi o to, by próbowac złamać program. Trzeba być pomysłowym, złośliwym i dobrze się przy tym bawić. Testowanie zmian stanów
Jak dotąd testowaliśmy jedynie dane – liczby, słowa, dane wejściowe i dane wyjściowe. Teraz zaczniemy sprawdzać, jak program przechodzi przez różne swoje stany. Stan programu to jego aktualny stan lub tryb działania. Spójrzmy na rysunki 5.8 i 5.9.
Rysunek 5.8 Program Paint w Windowsach w trybie rysowania ołówkiem.

Rysunek 5.7 Program Paint w Windowsach w trybie malowania rozpryskiwaczem.
Rysunek 5.8 pokazuje program Paint w Windowsach w trybie rysowania ołówkiem. Jest to stan początkowy po starcie programu. Zwróćmy uwagę, że wybrawszy jako narzędzie ołówek, kursor przybiera kształt ołówka, a na ekranie rysuje się cienka linia. Rysunek 5.9 pokazuje ten sam program w trybie malowania rozpryskiwaczem. W tym stanie podane są rozmiary rozpryskiwacza, kursor wygląda jak puszka farby z rozpryskiwaczem, a linia wygląda jak spryskana farbą.

Spójrzmy bliżej na rozmaite opcje, jakie oferuje program Paint – wszystkie narzędzia, pozycje menu, kolory itd. Kiedy wybiera się jedną z tych opcji i program zmienia wygląd, rodzaje dostępnych komend, działanie – to znaczy że zmienił się jego stan. Program wykonuje kod: zmienia wartośc kilku bitów, przydziela wartość kilku zmiennym, ładuje jakieś dane – i zmienia stan.
Tester musi przetestować wszystkie stany programu i przejścia między nimi.