rozdział 7
08 września 2019, 21:02
Rozdział 7 Testowanie pod rentgenem
W TYM ROZDZIALE Dynamiczne testowanie metodami szklanej skrzynki Dynamiczne testowanie a lokalizowanie i usuwanie błędów Test komponentów Pokrycie danych Pokrycie kodu
Jak dotąd w części II-iej poznaliśmy trzy spośród czterech podstawowych technik testowania: statyczne testowanie metodami czarnej skrzynki (testowanie specyfikacji), dynamiczne testowanie metodami czarnej skrzynki (testowanie oprogramowania) i statyczne testowanie metodami szklanej skrzynki (badanie i analiza kodu źródłowego). W tym rozdziale zapoznamy się z czwartą podstawową techniką – dynamicznym testowaniem metodami szklanej skrzynki. Testując oprogramowanie, będziemy zaglądać do wnętrza „skrzynki” jakby przy pomocy rentgena.
Oprócz rentgenowskich okularów, trzeba też będzie wystąpić pod flagą programisty – o ile ma się do tego kompetencje. Jeśli komuś brak znajomości programowania, nie trzeba się zrażać. Podane w rozdziale przykłady nie są zanadto skomplikowane i przyłożywszy się, każdy jest w stanie je śledzić. Zrozumiawszy choć w części tę grupę technik testowych, można stać się o wiele skuteczniejszym testerm.
Jeśli ma się pewne doświadczenie w programowaniu, ten rozdział otwiera bardzo szerokie możliwości. Większość firm produkujących oprogramowanie zatrudnia testerów właśnie do testowanie na niskim poziomie. Poszukiwane są osoby mające umiejętności zarówno w programowaniu jak i w testowaniu, co jest rzadkim i często poszukiwanym połączeniem.
Najważniejsze punkty tego rozdziału: 157.Czym jest dynamiczne testowanie metodami szklanej skrzynki 158.Różnica między dynamicznym testowaniem metodami szklanej skrzynki a usuwaniem błędów z programu 159.Co to jest testowanie jednostkowe i testowanie integracyjne 160.Jak testować funkcje na niskim poziomie 161.Rodzaje danych które trzeba testować na niskim poziomie
162.Jak zmuszać program do wymaganego sposobu działania 163.Jakimi różnymi metodami można zmierzyć staranność testowania Dynamiczne testowanie metodami szklanej skrzynki
Znamy już na pewno bardzo dobrze pojęcia statyczny, dynamiczny, metody szklanej skrzynki i metody czarnej skrzynki, tak że wiedząc, że ten rozdział zajmie się testowaniem dynamicznym metodami szklanej skrzynki, powinniśmy się łatwo domyśleć jego treści. Skoro jest dynamiczne, to znaczy że program musi być uruchamiany, a skoro jest metodami szklanej skrzynki, to znaczy że zagląda się „do środka pudełka”, analizuje kod i obserwuje jak jest wykonywany. Testuje się jakby z rentgenem na oczach.
Dynamiczne testowanie metodami szklanej skrzynki posiłkuje się informacją zdobytą przez obserwowanie chodzącego kodu. Ta informacja jest wykorzystywana aby zadecydować co testować, czego nie testować, i w jaki sposób podejść do testowania. Inną powszechnie stosowaną nazwą na dynamiczne testowanie metodami szklanej skrzynki jest testowanie strukturalne, ponieważ widzi się przy nim i wykorzystuje strukturę kodu do konstruowania i do wykonywania zadań testowych.
Jakie pożytki mogą wynikać ze znajomości tego, co dzieje się „wewnątrz pudełka”, jak działa oprogramowanie? Spójrzmy na rysunek 7.1. Pokazane są na nim dwa pudełka, realizujące podstawowe operacje arytmetyczne: dodawanie, odejmowanie, mnożenie i dzielenie.
Rysunek 7.1 Wybrałoby się inne zadania testowe wiedząc, że pudełku jest komputer i inne, jeśli w pudełku siedziałby człowiek z papierem i ołówkiem.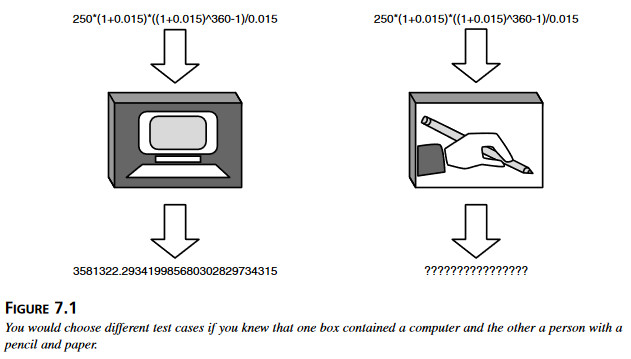 Jeśli nie wie się, jak działa pudełko, wybrałoby się dynamiczne techniki czarnej skrzynki, które zostały opisane w rozdziale 5-ym, „Testowanie z klapkami na oczach”. Gdyby jednak zajrzeć do pudełek i zobaczyć, że jedno z nich zawiera komputer, a w drugim ukrywa się człowiek z ołówkiem i papierem, wybrałoby się przypuszczalnie dla nich zupełnie odmienne zestawy testów. Oczywiście, to bardzo uproszczony przykład, ale dobrze ilustruje jak znajomość sposobu działania programu wpływa na sposób testowania.
Jeśli nie wie się, jak działa pudełko, wybrałoby się dynamiczne techniki czarnej skrzynki, które zostały opisane w rozdziale 5-ym, „Testowanie z klapkami na oczach”. Gdyby jednak zajrzeć do pudełek i zobaczyć, że jedno z nich zawiera komputer, a w drugim ukrywa się człowiek z ołówkiem i papierem, wybrałoby się przypuszczalnie dla nich zupełnie odmienne zestawy testów. Oczywiście, to bardzo uproszczony przykład, ale dobrze ilustruje jak znajomość sposobu działania programu wpływa na sposób testowania.
Dynamiczne testowanie metodami szklanej skrzynki oznacza więcej niz tylko oglądanie pracy kodu, może również oznaczać bezpośrednie testowanie i kontrolę oprogramowania. Dynamiczne testowanie metodami szklanej skrzynki obejmuje cztery obszary: 164.Bezpośrednie testowanie na niskim poziomie funkcji, procedur, rutyn i bibliotek. W Windowsach nazywane one są zwykle interfejsem programistycznym (API). 165.Testowanie oprogramowania na najwyższym poziomie, jako gotowy program, z tym że zadania testowe oparte są rónież na tym, co się wie o sposobach jego działania. 166.Uzyskanie dostępu do do zmiennych w kodzie i do informacji o jego stanie ułatwi sprzwdzenie, czy testy są właściwie skonstruowane. Również daje to możliwośc „zmuszenia” programu do innego działania , niż dałoby się osiągnąć testując tylko technikami czarnej skrzynki. 167.Pomiary, jaka część kodu i specyfikacji została rzeczywiście przetesowana – i uzupełnienie zestawu zadań testowych o nowe, jeśli nie idało się osiągnąć pożądanego pokrycia kodu.
Każdy z tych czterech obszarów będzie przedyskutowany w pozostałej części rozdziału. Warto to wziąć pod uwagę czytając dalej i zastanowić się, na ile te techniki przydałyby się do testowania programów. Dynamiczne testowanie a lokalizowanie i usuwanie będów
Nie należy mieszać dynamicznego testowania metodami szklanej skrzynki z lokalizacją i usuwaniem błędów. Kto zajmował się programowaniem, na pewno spędził wiele godzin lokalizując i usuwając błędy w napisanym przez siebie kodzie. Obie czynności wydaja się podobne, ponieważ obie zajmują się błędami w oprogramowaniu i obie „grzebią się” w kodzie, ale ich cele są zupełnie odmienne (rysunek 7.2).
Rysunek 7.2 Dynamiczne testowanie metodami szklanej skrzynki oraz lokalizowanie i usuwanie błędów mają różne cele, ale zazębiają się. Celem testowania jest znajdowanie błędów. Celem lokalizacji i usuwania błędów jest ich likwidacja. Te rejony zazębiają się tam, gdzie staramy się błąd wyizolowac i zidentyfikować jego przyczynę. Dowiemy się na ten temat więcej w rozdziale 18-ym „Raportowanie wyników”, ale na razie przyjmijmy uproszczone wytłumaczenie. Tester oprogramowania ma za zadanie zawęzic problem do naprostszego możliwego testu, który wywołuje symptom poszukiwanego błędu. Testując metodami szklanej skrzynki, możemy często nawet zidentyfikować ”podejrzany” fragment kodu. Programista zajmujący się lokalizowaniem i usuwaniem błędu przejmuje pałeczkę w tym właśnie miejscu, ustala dokładnie przyczynę błędu i usiłuje ją usunąć.
Celem testowania jest znajdowanie błędów. Celem lokalizacji i usuwania błędów jest ich likwidacja. Te rejony zazębiają się tam, gdzie staramy się błąd wyizolowac i zidentyfikować jego przyczynę. Dowiemy się na ten temat więcej w rozdziale 18-ym „Raportowanie wyników”, ale na razie przyjmijmy uproszczone wytłumaczenie. Tester oprogramowania ma za zadanie zawęzic problem do naprostszego możliwego testu, który wywołuje symptom poszukiwanego błędu. Testując metodami szklanej skrzynki, możemy często nawet zidentyfikować ”podejrzany” fragment kodu. Programista zajmujący się lokalizowaniem i usuwaniem błędu przejmuje pałeczkę w tym właśnie miejscu, ustala dokładnie przyczynę błędu i usiłuje ją usunąć.
Ważne jest umieć rozdzielić w praktyce pracę testera i programisty. Programiści piszą kod, testerzy szukają i znajdują błędy i czasem piszą nieco kodu do automatyzacji testów; programiści poprawiają błędy. Bez wyraźnego podziału, pewne zadania mogą zostać przez obie strony pominięte, albo – przeciwnie – jakaś praca zostanie wykonana dwa razy.
Testując na niskim poziomie w pobliżu kodu, używa się wielu tych samych narzędzi co programiści. Jeśli program jest kompilowany, tester również go kompiluje, ewentualnie z innymi ustawieniami dla umożliwienia łatwiejszego wykrywania błędów. Tester używa też prawdopodobnie tego samego programu śledzącego aby wykonywać program pojedynczymi krokami, obserwowac wartość zmiennych, ustawiać punkty zatrzymania itd. Często też pisze się własne programy, np. aby móc przetestować pojedyncze moduły. Testowanie kawałków
Przypomnijmy sobie z rozdziału 2-iego „Proces wytwarzania oprogramowania” różne modele wytwarzania oprogramowania. Model skokowy był najprostszy, ale też najbardziej chaotyczny. Wszystko łączy się ze sobą na raz, zaciska kciuki i można mieć nadziję, że powstanie z tego gotowy produkt. Łatwo się domyśleć, że testowanie przy tym trybie pracy jest bardzo trudne. Co najwyżej można przystąpić do testowania dynamicznego metodami czarnej skrzynki, biorąc program w jednym dużym kawałku i próbując, co też dałoby się znaleźć.
Nauczyliśmy się już że taka metoda jest bardzo kosztowna, ponieważ błędy znajduje się bardzo późno w procesie wytwórczym. Z punktu widzenia testu, istnieją dwie główne przyczyny tych wysokich kosztów: 168.Trudno – a czasem wręcz niemożliwe – jest zorientować się, co jest przyczyną awarii. Oprogramowanie jest jak zepsuty czarodziejski stolik – choć wypowiedziało się zaklęcie „stoliczku nakryj się”, żadne potrawy się nie pojawiły. Nie sposób zgadnąć, jaki drobiazg szwankuje i powoduje, że całość nie działa. 169.Jedne błędy mogą zasłaniać inne błędy. Zadanie testowe wywołuje awarię, programista spokojnie znajduje i usuwa błąd, ale kiedy wykonuje się zadanie testowe ponownie, znów następuje awaria. Tak wiele różnych błędów nałożyło się jedne na drugie, że bardzo czasochłonne robi się dotarcie do pierwszej przyczyny.
Test komponentów i test integracyjny
Żeby wybrnąć z tego całego bałaganu, najlepiej do niego po prostu nie dopuścić. Jeśli kod powstaje i jest testowany po kawałku, a potem stopniowo składa się go w większe całości, nię będzie tylu niespodzianek, kiedy w końcu połączy się cały produkt (rysunek 7.3).
Program główny Moduł Moduł …
Rysunek 7.3 Poszczególne fragmenty kodu buduje się i testuje pojedynczo, potem integruje ze sobą i testuje ponownie.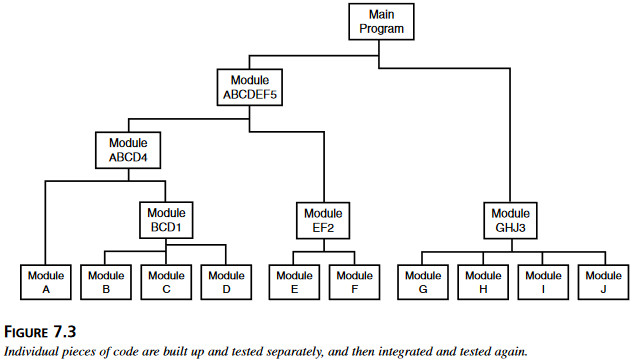 Testowanie na najniższym poziomie nazywane jest testowaniem jednostkowym&testowaniem komponentów albo testowaniem modułu1. Moduły są testowane, błędy w nich znajdowane i usuwane, po czym następuje integracja i test integracyjny grup modułów. Proces przyrostowego testowania przebiega stopniowo, łącząc ze sobą coraz więcej i więcej modułów, aż wreszcie cały produkt – a przynajmniej jego większa część – zostaje przetestowana w całości w ramach testowania systemu.
Testowanie na najniższym poziomie nazywane jest testowaniem jednostkowym&testowaniem komponentów albo testowaniem modułu1. Moduły są testowane, błędy w nich znajdowane i usuwane, po czym następuje integracja i test integracyjny grup modułów. Proces przyrostowego testowania przebiega stopniowo, łącząc ze sobą coraz więcej i więcej modułów, aż wreszcie cały produkt – a przynajmniej jego większa część – zostaje przetestowana w całości w ramach testowania systemu.
Kiedy stosuje się tę strategię testowania, identyfikacja i lokalizacja błędów stają się o wiele łatwiejsze. Problem znaleziony na poziomie modułu z reguły musi znajdować się w tym samym module. Jeśli następuje awaria podczas łączenia przedtem przetestowanych z osobna modułów, to jej źródłem jest przypuszczalnie interakcja między modułami. Zdarzają się wyjątki od tej zasady, ale ogólnie rzecz biorąc, testowanie i lokalizacja błędów przebiega wtedy znacznie sprawniej niż kiedy testuje się wszystko na raz.
Istnieją dwie główne metody integracji przyrostowej: oddolny i odgórny. W testowaniu oddolnym (rysunek 7.4) testerzy piszą własne procedury, zwane sterownikami, które przywołują testowany moduł. Podłącza się moduły dokładnie w ten sam sposób jak w pełnym programie. Sterowniki wysyłają dane testowe do testowanych modułów, odczytują wyniki i weryfikują, czy są poprawne. W ten sposób daje się zwykle przetestwoać oprogramowanie bardzo szczegółowo, przy użyciu bardzo różnorodnych danych testowych, nawet takich które trudno byłoby zastosować podczas testowania kompletnego systemu.
Rzeczywiste oprogramowanie
Temperatura Wyniki Moduł konwersji z oF na oC
Konfiguracja w świecie rzeczywistym
Oprogramowanie sterownika
Dane testowe Wyniki Moduł konwersji z oF na oC
Konfiguracja sterownika testowego
Rysunek 7.4 Sterownik testowy może zastąpić część oprogramowania i przetestować bardzo dokładnie moduł niższego rzędu.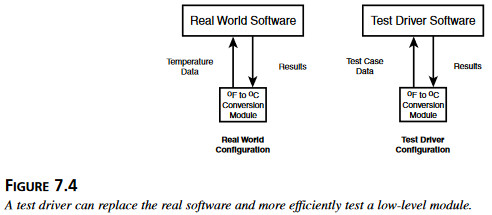
Integracja odgórna brzmi trochę jak skokowa w mniejszej skali. W końcu jeśli gotowy jest główny program, musi być za późno brać się za testowanie modułów? Nie całkiem jest to prawdą. Spójrzmy na rysunek 7.5. W tym wypadku, moduł interfejsu na niskim poziomie zbiera dane o temperaturze z elektronicznego termometru. Moduł wyświetlacza umieszczony jest tuż ponad interfejsem, skąd czyta dane i wyświetla je na ekranie dla użytkownika. Aby przetestować górny moduł wyświetlacza na gotowym systemie, trzeba by posługiwać się palnikami, woda, lodem i zamrażarką, żeby spowodować zmiany temperatury czujnika, przekazywane do modułu wyświetlającego.
Zamiast jednak testować moduł wyświetlacza usiłując sterować temperaturą termometru, można napisać fragment kodu, zwany namiastką, który działa tak jak interfejs, podając temperatury - zapisane np. na pliku - wprost do modułu wyświetlającego. Moduł wyświetlający odczytuje przekazywane dane tak samo, jakby je czytał wprost z interfejsu prawdziwego termometru. Nie jest w stanie dostrzec żadnej różnicy. Używając namiastek, można – w tym wypadku – szybko przetestować moduł wyświetlacza przy użyciu wielkiej ilości danych testowych i dokonać walidacji tego modułu.
Moduł wyświetlacza temperatury
Moduł interfejsu termometru
Konfiguracja w świecie rzeczywistym
Testowany moduł wyświetlacza temperatury
Namiastka skonstruowana przez testera
Plik z danymi testowymi
Konfiguracja sterownika testowego
Rysunek 7.5 Namiastka testowa przesyła dane do góry, do testowanego modułu.
Przykład testu modułu
Funkcją dostępną w wielu językach programowania jest konwersja ciągu znaków ASCII w wartość całkowitoliczbową.
Ta funkcja przyjmuje ciąg cyfr, znaki ‘-‘ lub ‘+‘ oraz możliwe dodatkowe znaki jak spacja oraz litery, i przekształca je w wartość liczbową. Na przykład, ciąg znaków „12345” zostaje przekształcony w liczbę dwanaście tysięcy trzysta czterdzieści pięć. Tej funkcji używa się często do przetwarzania danych z okna dialogowego – na przykład czyjś wiek albo inne dane.
W języku C ta funkcja nazywa się atoi(), co jest skrótem nazwy „ASCII na liczbę całkowitą”1. Rysunek 7.6 pokazuje specyfikację tej funkcji. Kto nie jest programistą, nich się nie denerwuje. Oprócz pierwszej linijki, określającej jak funkcję się przywołuje, specyfikacja jest napisana w zwykłej polszczyźnie i można jej używać do opisu tej samej funkcji dla dowolnego języka programowania.
Co powinien zrobić tester, któremu przypadło zadanie wykonania dynamicznego testowania – metodami szklanej skrzynki – tego modułu?
int atoi (const char *string) Funkcja „z ASCII na liczbę całkowitą” przekłada ciąg znaków na liczbę całkowitą.
Wartość powrotna Funkcja zwraca wartość całkowitoliczbową, powstałą przez potraktowanie ciągu znaków na wejściu jako zapisu liczby. Wartość powrotna wynosi 0 jeśli dane z wejścia nie dadzą się przkształcić na liczbę całkowitą. Wartość powrotna jest niezdefiniowana w wypadku przepełnienia.
Parametr wejściowy ciąg znaków Ciąg znaków który ma być przekształcony.
Uwagi Ciąg znaków na wejściu jest sekwencją znaków, którą można zinterpretować jako wartość liczbową. Funkcja przestaje czytać ciąg znaków po natrafieniu na pierwszy znak, którego nie daje się zinterpretować jako części składowej liczby. Ten znak może być znakiem zerowym (`\0`) zakańczającym ciąg znaków.
Ciąg znaków dla tej funkcji ma postać: [pusty znak] [znak plus/minus] cyfry
Pusty znak może być spacją i/albo znakiem tabulacji, które są pomijane; znak plus/minus to albo plus (+), albo minus (-); cyfry to to jeden lub więcej cyfr dziesiętnych. Funkcja nie rozpoznaje punktu dziesiętnego, potęg ani żadnych innych, niewymienionych powyżej znaków. Rysunek 7.6 Specyfikacja funkcji atoi() w języku C. Wydaje się od razu, że ten moduł wygląda jak moduł na najniższym poziomie, taki który jest przywoływany przez inne moduły, ale sam niczego nie przywołuje. Można to ewentualnie potwierdzić, czytając kod modułu. Jeśli tak jest, to logiczną metodą będzie napisanie sterownika testowego, aby móc sprawdzać ten moduł niezależnie od reszty programu.
Specyfikacja funkcji atoi() w języku C. Wydaje się od razu, że ten moduł wygląda jak moduł na najniższym poziomie, taki który jest przywoływany przez inne moduły, ale sam niczego nie przywołuje. Można to ewentualnie potwierdzić, czytając kod modułu. Jeśli tak jest, to logiczną metodą będzie napisanie sterownika testowego, aby móc sprawdzać ten moduł niezależnie od reszty programu.
Sterownik testowy wysyłałby skonstruowane przez testera ciągi znaków do funkcji atoi(), odbierał wynik i porównywał go z oczekiwanym rezultatem. Najprawdopodobniej, sterownik testowy zostałby napisany w tym samym języku, co testowana funkcja – w tym wypadku, w języku C – ale daje się też pisać sterowniki w innych językach, byle miały one interfejs do języka, w którym napisany jest testowany moduł.
Sterownik testowy może przybierać różne kształty. Może to być proste okno dialogowe, jak na rysunku 7.7, którego używa się do wprowadzania ciągów znaków i do obserwacji wyników. Mógłby to być osobny program, czytający ciągi znaków i oczekiwane wyniki z pliku. Okno dialogowe, sterowane przez użytkownika, jest interakcyjne i bardzo elastyczne – można je udostępnić rónież testerowi stosującemu techniki czarnej skrzynki. Z drugiej strony, osobny program może działać o wiele szybciej, czytając dane testowe i zapisując wyniki bezpośrednio na pliku. 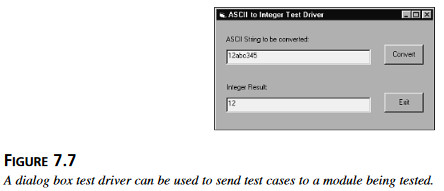 Rysunek 7.7 Sterownik testowy w postaci okna dialogowego może być zastosowany, aby posyłać zadania testowe testowanemu modułowi.
Rysunek 7.7 Sterownik testowy w postaci okna dialogowego może być zastosowany, aby posyłać zadania testowe testowanemu modułowi.
Następnie należałoby zanalizować specyfikację i zadecydować, jakie zadania testowe typu czarnej skrzynki warto wypróbować, a w końcu zastosować podział na klasy równoważności aby zmniejszyć ich ilość (przypomnijmy sobie rozdział 5-y). Tabela 7.1 pokazuje przykłady zadań testowych wraz z ciągami znaków stosowanych jako dane wejściowe oraz oczekiwanymi wynikami wyjściowymi. Tabela ta nie ma być wyczerpująca.
Tabela 7.1 Przykładowe zadania do testowania przekształcenia ciągu ASCII w liczbę całkowitą.
Ciąg znaków (na wejściu) Wartość na wyjściu „1” 1 „-1” -1 „+1” 1 „0” 0 „-0” 0 „+0” 0 „1.2” 1 „2-3” 2 „abc” 0 „a123” 0 i tak dalej
Wreszcie należałoby również rzucić okiem na kod źródłowy, zobaczyć z jaki sposób zrobiono implementację funkcji i wykorzystac tę „szkalnoskrzynkową” wiedzę na temat modułu, aby dodać lub usunąć zdania testowe.
Ważne, aby zadanie testowe typu „czarnoskrzynkowego”, oparte na specyfikacji, konstruować zanim zacznie się stosowac metody szklanej skrzynki. W ten sposób testuje się w pierwszy rzędzie to, co moduł powinien wykonywać. Jeśli natomiast zacząć od zadań testowych sporządzonych według metod szklanej skrzynki, to jest poprzez analizę kodu, łatwo zatracić bezstronność i konstruować zadania testowe na podstawie tego, jak moduł rzeczywiście działa. Jednak programista mógł przecież nie zrozumieć specyfikacji i wtedy zadania testowe skonstruowane przez testera będą tak samo błędne. Owszem, mogą być dokładne, znakomicie „testujące” moduł, ale nie będą trafne, ponieważ nie będą testować właściwego działania.
Dodawanie i odrzucanie zadań testowych przy użyciu wiedzy na temat kodu jest w istocie szczególnym zastosowaniem metody podziału na klasy równoważności przy zastosowaniu informacji „wewnętrznych”. Pierwotne zadania testowe mogły zakładać, że zadania takie jak „a123” i „z123” są istotnie różne. Analiza kodu mogłaby jednak ujawnić, że zamiast posługiwać się tabelą ASCII, programista ograniczyl się do poszukiwania znaków pustych, znaków ‘+‘ i ‘-‘ oraz cyfr. Mając tę informację, jedno z powyższych zadań testowych można spokojnie odrzucić, ponieważ oba znajdują się w tej samej klasie równoważności.
Inna sytuacja – dokładniejsza analiza kodu mogłaby na przykład ujawnić, że identyfikowanie znaków ‘+‘ i ‘-‘ wygląda trochę podejrzanie – może po prostu trudno jest je zrozumieć. W tej sytuacji, warto dla upewnienia się dodać kilka zadań testowych ze znakami ‘+‘ i ‘-‘ rozrzuconymi w różnych miejscach. Pokrycie danych Powyższy przykład testowania funkcji atoi() metodami szklanej skrzynki był znacznie uproszczony i pomijał wiele szczegółów na temat wpływu analizy kodu na dobór zadań testowych. W rzeczywistości analiza kodu jest czymś więcje niż źródłem dobrych poysłów, co testować, a czego nie warto.
Należy – tak samo jak to się robi w testowaniu metodami czarnej skrzynki – podzielić kod na dane i stany (albo przepływ sterowania). Stosując ten punkt widzenia, o wiele łatwiej odnieść uzyskaną informację na temat kodu do wcześniej skonstruowanych zadań testowych metodami czarnej skrzynki.
Weźmy najpierw pod uwagę dane. Do danych zaliczają się wszystkie zmienne, stałe, wektory, inne struktury danych, dane wejściowe z klawiatury i z myszy, dane wejściowe i wyjściowe z plików i z ekranu, wjeście/wyjście z innych urządzeń jak modemy, sieci i tak dalej.
Przepływ danych
Badanie pokrycia przepływu danych polega na prześledzeniu całej drogi przez fragment programu jednego „kawałka” danych. Na poziomie testowania jednostkowego oznacza to przepływ danych przez pojedynczy moduł. Można także prześledzić drogę danych przez kilka zintegrowanych modułów albo nawet przez całe oprogramowanie – aczkolwoiek byłoby to bardzo czasochłonne.
Testując funkcję na tak niskim poziomie, używa się programu śledzącego i obserwuje wartości zmiennych w czasie wykonywania programu (rysunek 7.8). Stosując testowanie czarnej skrzynki, zna się tylko wartość zmiennej na początku i na końcu. Stosując dynamiczne testowanie szklanej skrzynki, można też sprawdzać wartości pośrednie podczas wykonywania programu. Biorąc pod owagą poczynione obserwacje, można zmodyfikować zadania testowe tak, aby wymusić przyjęcie przez zmienne interesujących czy ryzykownych wartości pośrednich.
Rysunek 7.8 Program śledzący i obserwacja zmiennych umożliwia śledzenie wartości zmiennych w czasie wykonywania programu.
Wewnętrzne wartości graniczne
Wewnętrzne wartości graniczne omawiane już były w rozdziale 5-ym w odniesieniu do wbudowanych tabel ASCII i do wartości potęgi dwójki. To są przypuszczalnie najczęściej spotykane wewnętrzne wartości graniczne powodujące błędy, ale każdy fragment kodu będzie też miał swoje własne, specjalne wewnętrzne wartości graniczne. Oto kilka przykładów: 170.Moduł służący do wyliczania podatków może przy progu podatkowym zmienić sposób naliczania z tabeli wartości na użycie arytmetycznego wyrażenia do obliczeń. 171.System operacyjny może zacząć przenosić dane do pamięci tymczasowej na dysku kiedy zaczyna brakować pamięci RAM. Wartość tej granicy nie musi być nawet ustalona z góry, może się zmieniać zależnie od tego, ile miejsca pozostało na dysku.
172.Dla uzyskania większej dokładności, złożony algorytm numeryczny może zmieniać użwaną formułę obliczeń zależnie od wielkości liczby.
Przy testowaniu metodami szkalnej skrzynki należy uważnie badać kod w poszukiwaniu wewnętrznych wartości granicznych, aby móc dorobić dla nich dodatkowe zadania testowe. Warto spytać programistę, który napisał kod, czy potrafi zidentyfikować takie miejsca, i zwrócić baczną uwagę na wewnętrzne tabele danych, które są szczególnie podatne na problemy wewnętrznych wartości granicznych.
Wzory i równania
Bardzo często wzory i równania ukryte są głęboko w kodzie i ich obecność ani skutki nie są oczywiste, kiedy się patrzy z zewnątrz. Program finansowy do obliczania procentu złożonego na pewno będzie gdzieś zawierał nastąpujący wzór:
A = P (1 + r/n)nt
gdzie P = suma wyjściowa r = roczna stopa procentowa n = ilość razy, kiedy w ciągu roku nalicza się procent t = ilość lat A = suma po upływie czasu t Dobry tester posługujący się metodami czarnej skrzynki wybrałby, należy mieć nadzieję, zadanie testowe gdzie n=0, ale tester stosujący metody szklanej skrzynki, zobaczywszy ten wzór w kodzie, na pewno zastosuje n=0, ponieważ spowoduje się w ten sposób awarię wzoru i błąd dzielenia przez zero. Cóż się jednak stanie, jeśli wartość n jest wynikiem innych obliczeń? Może program ustala wartość n na podstawie danych wprowadzanych przez użytkownika, albo algorytm wypróbowuje różne warotści n w celu znalezienia takiej, dla której wynik będzie najniższy. Należy zadać sobie pytanie, czy istnieje możliwość, że n kiedykoliwek otrzyma wartość zero i odkryć, jakie dane trzeba wprowadzic do programu aby to uzyskać.
Należy przeszukiwać kod w poszukiwaniu wzorów i równań, badać używane w nich zmienne i konstruować zadania testowe oparte na dodatkowych klasach równoważności, jako dodatek do klas równoważości dla danych wejściowych i wyjściowych programu.
Wymuszanie awarii
Ostatnim rodzajem omawianych w tym rozdziale testów opartych na danych jest wymuszanie awarii. Jeśli używa się programu śledzącego, można nie tylko obserwować warości zmiennych, ale również je modyfikować.
W omawianym przykładzie obliczania procentu złożonego, jeśli nie znajduje się sposobu nadania zmiennej n wartości zerowej, można nadać jej warość zero przy pomocy programu śledzącego. Program albo sobie z tym poradzi… albo nie.
Warto pamiętać, że przy pomocy programu śledzącego można stworzyć sytuację, która nigdy nie może zaistnieć przy normalnym użytkowaniu programu. Jeśli program kontroluje że warość n jest większa od zera na początku funkcji, a zmiennej n później do niczego co może zmienić jej wartość już się nie używa, to nadanie jej wartości zerowej i spowodowanie w ten sposób awarii programu jest niedozwolonym zadaniem testowym.
Wymuszanie awarii może być skuteczną metodą, o ile stosować ją ostrożnie i z namysłem, sprawdzając razem z programistami, że wybrane zadania testowe są dozwolone. Można w ten sposób wykonywac zadania testowe, w przeciwnym razie trudne lub niemożliwe do osiągnięcia.
Wymuszanie komunikatów o błędach
Wymuszanie awarii jest świetną techniką, aby wywołać pojawienie się wszelkich możliwych komunikatów o błędach, ukrytych w programie. Wiele programów stosuje wewnętrzne kody dla oznaczenia każdego komunikatu o awarii. Kiedy wewnętrzna flaga sygnalizująca błąd jest ustawiona, procedura obsługi błędu odczytuje zmienną zawierającą ten kod i wyświetla odpowiedni komunikat.
Wiele błędów trudno jest zaaranżować – jak na przykład podłączenie 2049 drukarek. Jeśli jednak chce się tylko skontrolować, że poprawny jest sam komunikat o błędzie, (ortografia, słownictwo, format itd), wymuszanie błędów może być bardzo skutecznym sposobem, żeby je wszystkie zobaczyć. Trzeba tylko pamiętać, że w ten sposób testuje się kod wyświetlający komunikat o błędzie, a nie kod wykrywający błąd. Pokrycie kodu
Tak jak z testowaniem metodami czarnej skrzynki, testowanie danych to dopiero połowa bitwy. Dla osiągniecia wyczerpującego pokrycia należy również przetestować stany programu i przepływ kontroli między nimi. Trzeba sprawdzić wejścia i wyjścia każdego modułu, wykonać każdą linijke kodu, i prześledzić każdą ścieżkę przez program1. Badanie oprogramowania na tym poziomie nosi nazwę analizy pokrycia kodu.
Analiza pokrycia kodu jest dynamiczną techniką szklanej skrzynki, ponieważ wymaga pełnego dostępu do kodu, aby móc obserwować te fragmenty programu, przez które się przechodzi podczas wykonywania zadań testowych.
Najprostszą formą analizy pokrycia kodu jest zastosowanie programu śledzącego, by obserwować które linie kodu się przechodzi podczas jego wykonywania pojedynczymi krokami. Rysunek 7.9 pokazuje przykład programu śledzącego dla Visual Basic w działaniu.
Rysunek 7.9 Program śledzący umożliwia przyjście programu pojedynczymi krokami aby skontrolować, które linie kodu i które moduły przechodzi się podczas wykonywania zadań testowych.
Dla bardzo małych programów albo pojedynczych modułów ten sposób może być całkiem zadowalający. Jednak aby móc przeprowadzić analizę pokrycia kodu dla większości programów, trzeba się posługiwać specjalnym narzędziem, zwanym jako analizator pokrycia kodu. Rysunek 7.10 pokazuje przykład takiego narzędzia.
Analizator pokrycia kodu podłącza się do testowanego programu i jest egzekwowany w tle, kiedy wykonuje się zadania testowe. Kiedy wykonywanie przechodzi przez funkcję, linijkę kodu albo punkt decyzyjny, analizator zapisuje informację o tym. Po zakończonym wykonywaniu można uzyskać dane statystyczne, które identyfikują fragmenty kodu, przez które się przeszło i te, przez które się nie przeszło podczas testowania. Mając te dane wie się następujące rzeczy:
173.Które części kodu nie zostały pokryte przez zastosowane testy. Jeśli kod znajduje się w odrębnym module, którego się nigdy nie przeszło, wiadamo że trzeba się zabrać za tworzenie dodatkowych zadań testowych, aby przetestować działanie tego modułu.
Rysunek 7.10 Analizator pokrycia kodu dostarcza szczegółowych danych o skuteczności zastosowanych zadań testowych (rysunek jest własnością i został wydrukowany za zezwolenienm Bullseye Testing Technology.)  174.Które zadania testowe są zbędne. Jeśli wykonanie serii zadań testowych nie zwiększa stopnia pokrycia kodu, to przypuszczalnie należą wszystkie one do tej samej klasy równoważności. 175.Jakie nowe zadania testowe trzeba skonstruować aby osiągnąć lepsze pokrycie. Należy zanalizować fragmenty kodu gdzie pokrycie jest słabe, zrozumieć jego działanie i sporządzić nowe zadania testowe, które wykorzystają ten kod.
174.Które zadania testowe są zbędne. Jeśli wykonanie serii zadań testowych nie zwiększa stopnia pokrycia kodu, to przypuszczalnie należą wszystkie one do tej samej klasy równoważności. 175.Jakie nowe zadania testowe trzeba skonstruować aby osiągnąć lepsze pokrycie. Należy zanalizować fragmenty kodu gdzie pokrycie jest słabe, zrozumieć jego działanie i sporządzić nowe zadania testowe, które wykorzystają ten kod.
Osiąga się także wyczucie jakości testowanego oprogramowania. Jeśli pokrycie kodu wynosi 90% i nie znajduje się wielu błędów, oprogramowanie jest zapewne w dobrym stanie. Jeśli, przeciwnie, testy osiągnęły ledwo 50% pokrycia kodu i nadal znajduje się błędy, trzeba spodziewać się jeszcze wiele pracy.
Pokrycie linii kodu
Najprostszą formą pokrycia kodu jest tak zwane pokrycie instrukcji albo pokrycie linii kodu. Monitorowanie pokrycia instrukcji w trakcie testowania oznacza zwykle, że celem jest wykonanie choć raz każdej instrukcji w programie. Dla krótkiego programu, jak ten na wydruku 7.1, 100% pokrycia instrukcji oznacza wykonanie linii od 1-ej do 4-ej.
Wydruk 7.1 Bardzo łatwo jest przetestować każdą linię tego prostego programu PRINT „Czołem, Świecie”
PRINT „Dzisiejsza data: „; Date$ PRINT „Jest godzina: „; Time$ END Nietrudno ulec złudzeniu, że 100% pokrycia instrukcji oznacza, że program został przetestowany całkowicie. Celem i sygnałem do zaprzestania testów byłoby osiągniecie 100% pokrycia. Niestety, to tylko złudzenie. Przetestowanie każdej instrukcji programu nie oznacza, że przetestowało się również wszystkie możliwe ścieżki przez program.
Pokrycie rozgałęzień programu
Testowanie w celu pokrycia jak największej ilości możliwych ścieżek przez program nazywane jest testowaniem ścieżek. Najprostszą formą testowania ścieżek jest testowanie rozgałęzień. Spójrzmy na program pokazany na wydruku 7.2.
Wydruk 7.2 Instrukcja IF stwarza rozgałęzienie w kodzie PRINT „Czołem Świecie„ IF Date$ = „2000-01-01” THEN PRINT „Dosiego Roku!” ENDIF PRINT „Dzisiejsza data: „; Date$ PRINT „Jest godzina: „; Time$ END Jeśli ma się na celu osiągnąć 100% pokrycia instrukcji, wystarczy jedno zadanie testowe, gdzie zmienna Date$ ma wartość 1 stycznia 2000. Program wykona wówczas następującą ścieżkę:
Linie 1, 2, 3, 4, 5, 6, 7
Analizator pokrycia kodu określiłby, że przetestowana została każda instrukcja i że osiągnięto 100% pokrycia. No to jesteśmy gotowi z testowaniem, prawda? Nieprawda! Przetestowana została każda instrukcja, ale nie każde rozgałęzienie.
Instynkt podpowiada, że należałoby jeszcze wykonać zadanie testowe z datą inną niż 1-y stycznia 2000. Wówczas program wykona inną ścieżkę:
Linie 1, 2, 5, 6, 7
Większość analizatorów pokrycia podaje osobno wyniki pokrycia instrukcji i pokrycia rozgałęzień, co pozwala sobie wytworzyć o wiele lepsze pojęcie o skuteczności testowania.
Pokrycie warunków logicznych
Kiedy juz myśleliśmy, że wszystko gotowe, pojawia się nowa trudnośc w testowaniu ścieżek. Wydruk 7.3 jest odmianą wydruku 7.2. Dodany został nowy warunek do instrukcji IF w drugiej linii, kontrolujący zarówno czas jak i datę. Testowanie warunków logicznych uwzględnia złożone warunki logiczne w instrukcji warunkowej.
Wydruk 7.3 Złożony warunek w instrukcji IF powoduje, że pojawia się więcej różnych ścieżek przez kod PRINT „Czołem Świecie„ IF Date$ = „2000-01-01” AND Time$ = „00:00:00” THEN PRINT „Dosiego Roku!” ENDIF PRINT „Dzisiejsza data: „; Date$ PRINT „Jest godzina: „; Time$ END Aby uzyskać pełne pokrycie warunków logicznych w tym przykładowym programie, potrzebne są cztery grupy danych testowych, jak pokazano w tabeli 7.2. Te dane gwarantują pokrycie wszelkich możliwości w instrukcji IF.
Tabela 7.2 Zadania testowe potrzebne dla osiągnięcia pełnego pokycia warunku IF ze złożonym warunkiem logicznym
Date$ Time$ Wykonanie linii 0000-01-01 11:11:11 1,2,5,6,7 0000-01-01 00:00:00 1,2,5,6,7 2000-01-01 11:11:11 1,2,5,6,7
2000-01-01 00:00:00 1,2,3,4,5,6,7
Jeśli interesuje nas tylko pokrycie rozgałęzień, trzy pierwsze grupy danych nie będą interesujące i mozna je połączyć w jedną klasę równoważności i w jedno zadanie testowe. Kiedy jednak stosuje się miarę pokrycia warunków logicznych, wszystkie cztery zadania są istotne, ponieważ reprezentują cztery różne warunki logiczne.
Analizatory pokrycia kodu mogą zwykle zostać skonfigurowane tak, by pokazywały również pokrycie warunków przy raportowaniu wyników. Kiedy się osiąga pokrycie warunków logicznych, osiąga się zarazem pokrycie rozgałęzień i pokrycie instrukcji.
Nawet jeśli przetestuje się każdą instrukcję, każde rozgałęzienie i każdy warunek logiczny (co jest możliwe tylko dla najmniejszych programów), nadal jeszcze nie przetestowało się wszystkiego. Zwróćmy np. uwagę, że wszysktkie błędy danych, opisane na początku tego rozdziału, nadal są możliwe. Przepływ kontroli i przepływ danych łącznie stwarzają działające oprogramowanie. Podsumowanie
W tym rozdziale dowiedzieliśmy się, jak dostęp do kodu źródłowego w czasie wykonywania programu otwiera cały nowy rozdział testowania oprogramowania. Dynamiczne testowanie metodami szklanej skrzynki upraszcza pracę testera, dając mu wgląd w ukrytą informację, co warto jest przetestować. Poznawszy szczegóły kodu, można eliminować zbędzne zadania testowe i dodawać nowe zadania w miejscach, których istnienia nawet się z początku nie podejrzewało. I jedno, i drugie poprawi wydajnośc testowania.
W rozdziałach 4 – 7 ponaliśmy podstawowe zasady testu oprogramowania: 176.Statyczne testowanie metodami czarnej skrzynki, polegające na badaniu specyfikacji i wyszukiwaniu problemów zanim jeszcze zostaną wpisane w kod programu. 177.Dynamiczne testowanie metodami czarnej skrzynki, polegające na testowaniu oprogramowania bez znajomości wewnętrznych mechanizmów jego działania. 178.Stayczne testowanie metodami szklanej skrzynki, polegające na badaniu szczegółów kodu źródłowego w postaci formalnych przeglądów i inspekcji. 179.Dynamiczne testowanie metodami szklanej skrzynki, gdzie obserwuje się działanie wewnętrznych mechanizów programu i dopasowuje zadania testowe do otrzymanej tą drogą informacji.
W pewnym sensie, te cztery rozdziały obejmują wszystko, co najważniejsze w testowaniu oprogramowania. Oczywiście, przeczytać w książce a umieć zastosować w praktyce to zupełnie co innego. Trzeba wiele zaangażowania i ciężkiej pracy, żeby zostać dobrym testerem. Żeby umieć zastosować te podstawowe techniki w praktyce, wiedzieć która pasuje najlepiej w jakiej sytuacji, trzeba wiele praktyki i doświadczenia.
W części 3-ej „Zastosowanie umiejętności w praktyce” poznamy różne dziedziny testowania i zastosowanie umiejętności z „czernej skrzynki” i ze „szklanej skrzynki” do rozmaitych rzeczywistych scenariuszy. Pytania
Pytania mają na celu ułatwienie zrozumienia. W aneksie A „Odpowiedzi do pytań” znajdują się prawidłowe rozwiązania – ale nie należy ściągać! 1.W jaki sposób znajomość wewnętrznych mechanizmów działania programu wpływa na to, jak i co należy przetestować? 2.Czy jest różnica między dynamicznym testowaniem metodami szklanej skrzynki, a lokalizowaniem i usuwaniem błędów? 3.Jakie są dwa główne powody, dla których testowanie jest niemal niewykonalne w modelu skokowym wytwarzania oprogramowania? Jak można im zaradzić? 4.Prawda czy fałsz: jeśli projektowi brakuje czasu, można przeskoczyć testowanie modułów (jednostkowe) i przystąpić od razu do tesowania integracyjnego. 5.Jaka jest różnica między namiastką testową a sterownikiem testowym? 6.Prawda czy fałsz: zawsze należy najpierw skonstruować zadania testowe metodami czarnej skrzynki. 7.Która jest najlepsza spośród trzech opisanych w tym rozdziale metod pomiaru pokrycia? Dlaczego? 8.Jaka jest najpoważniejsza trudność testowania metodami szklanej skrzynki, zarówno statycznego jak i dynamicznego?