rozdział 5 2/2
07 września 2019, 22:18
Test przepływu przejść między stanami programu
W rozdziale 3-im pokazano przykład, że testując Kalkulator ma się do czynienia z nieskończoną ilością kombinacji danych wejściowych dla programu. Jednocześnie nauczyliśmy się w kolejnych rozdziałach, że aby testowanie stało się możliwe, trzeba zmniejszyc ilość zadań testowych tworząc klasy równoważności dla najważniejszych grup wartości.
Testowanie stanów i przejść między nimi sprawia ten sam kłopot. Zwykle da się odwiedzić wszytkie stany (w końcu, gdyby się nie dało, można by je po prostu usunąć z programu). Kłopot w tym, że – z wyjątkiem rzeczywiście najprostszych programów, zwykle nie da się przebyć wszystkich możliwych ścieżek do wszystkich stanów. Złożoność oprogramowania, zwłaszcza z powodu bogactwa intefejsów użytkownika we współczesnych aplikacjach, stwarza tak wiele różnych wyborów i opcji, że ilość dostępnych ścieżek rośnie wykładniczo.
Ten problem przypomina dobrze znany problem komiwojażera: mając określony zbiór miast i odległości między nimi, znaleźć najkrótszą z dróg, która przejdzie przez wszystkie miasta i wróci do punktu wyjścia. Gdyby miast było tylko pięć, po dokonaniu obliczeń można stwierdzić, że możliwych tras przez nie jest 120. Przejechanie wszystkich i zmierzenie ich długości nie jest więc niewykonalne. Ale, jeśli zadanie dotyczy setek lub tysięcy miast – albo, w naszym przykładzie, setek albo tysięcy stanów programu – problem staje się bardzo trudny do rozwiązania.
Rozwiązeniem (dla testowania, nie dla komiwojażera) jest zastosowanie techniki podziału na klasy równoważności stanów i przejść między nimi. Stwarza się w ten sposób ryzyko, bo nie przetestuje się wszystkiego, ale można je zredukować dokonując inteligentnych wyborów.
Stworzenie mapy przejść stanów
Pierwszym krokiem będzie stworzenie włanej mapy przejść stanów programu. Czasami taka mapa jest dostępna jako część specyfikacji produktu. Jeśli tak jest, trzeba ją przetestować metodami statycznymi, jak to opisano w rozdziale 4-ym „Testowanie Specyfikacji”. Jeśli mapa przejść stanów nie istnieje, trzeba ją będzie zbudować.
Istnieją różne techniki zapisywania diagramów przejść stanów programu. Rysunek 5.10 pokazuje dwa przykłady. Na jednym rysuje się prostokąty i strzałki, a drugim kółka i strzałki1. Technika jest nieważna, o ile wszyscy członkowie zespołu umieją się nią posłużyć.
Rysunek 5.10 Diagramy przejśc stanów można rysowac na różne sposoby.

Diagramy przejść stanów łatwo staja się bardzo duże. Często widzi się całe ściany oklejone wydrukami diagramów. Istnieją programy rysujące takie diagramy – warto się nimi posłużyć.
Mapa przejść stanów powinna zawierać następujące elementy: 62.Każdy unikalny stan w którym program może się znaleźć. Prosta zasada brzmi – jeśli trudno się zdecydować, czy ma się do czynienia z jednym czy dwoma odrębnymi stanami, to zapewne są to dwa odrębne stany. Zawsze można później łatwo połączyć dwa stany z powrotem w jeden, jeśli to założenie okaże się niesłuszne. 63.Dane wejściowe które powodują przejście z jednego stanu do drugiego. Może to być naciśnięcie klawisza, dane z czujnika, dzwonek telefonu itd. Stanu nie można opuścić bez powodu. Ten powód właśnie usiłuje się tutaj zidentyfikować.
1 Oczywiście, różnica jest mniej niż kosmetyczna, w obu tych “różnych” technikach opisuje się stany i ich przejścia w formie grafu. Rzeczywiście odmienną (i znacznie wygodniejszą) techniką jest natomiast opis w formie tabeli, gdzie rzędy oznaczają stany wyjściowe, kolumny – stymulacją lub dane wejściowe, a pola na przecięciu rzędów i kolumn – stany docelowe (przyp. tłumacza).
64.Wyprodukowane dane wyjściowe albo inna zmiana warunków przy przejściu ze stanu do stanu. Może to być na przykład wyświetlenie menu albo zestawu przycisków, ustawienie flagi, pojawienie się wydruku, wykonanie obliczenia itd; wszystko, co dzieje się w trakcie przejścia z jednego stanu w drugi.
Testując przejścia stanów, zwykle robi się to w formie testowania metodą czarnej skrzynki, wobec czego nie musi się znać np. zmiennych w kodzie programu, które ustawiane są w trakcie przejść między stanami. Mapę stanów programu najlepiej sporządzić z punktu widzenia użytkownika.
Zmniejszenie ilości stanów i ich przejść, które się będzie testować
Sporządzenie mapy stanów dla dużego produktu informatycznego to wielkie przedsięwzięcie. Jeśli testuje się tylko część produktu, np.podsystem, wykonanie mapy stanów staje się łatwiejsze. Kiedy mapa jest gotowa, można obejrzeć opis wszystkich stanów i przejść między nimi – i to jest groźny widok!
Gdyby mieć do dyspozycji nieskończoną ilość czasu, można by przetestować wszystkie ścieżki prowadzące przez diagram stanów – nie tylko przejścia między dwoma sąsiednimi stanami, ale wszelkie możliwe kombinacje przejść od początku do końca, z różną ilością powtórzeń, pętalmi itp. Podobnie jak w problemie komiwojażera, nie da się przetestować wszystkich.
Jak podział na klasy równoważności stosuje się wobec danych, tak samo można ograniczyć ilość zadań testowych dla testów przejść stanów. Jest na to pięć sposobów: 65.Odwiedzić każdy stan przynajmniej jeden raz. Nieważne jak, ważne aby się tam dostać. 66.Przetestować przejścia ze stanu do stanu, które wydają się najczęściej odwiedzane. To brzmi – i jest – bardzo subiektywne, ale można podeprzeć się wiedzą zdobytą, gdy przeprowadzało się statyczną analizę metodą czarnej skrzynki (rozdział 3) na specyfikacji produktu. Niektóre scenariusze zastosowań okazują się być wykonywane częściej niż inne – i one muszą działać dobrze! 67.Przetestować najrzadziej używane ścieżki między parami stanów – być może zostały one przeoczone przez konstruktorów i programistów. Tester będzie jednym z pierwszych, który je wypróbuje.
68.Przetestować każdy ze stanów awaryjnych oraz powroty z nich. Wiele stanów awaryjnych trudno jest wywołać. Niejednokrotnie programiści piszą kod dla obsługi różnych awarii, ale nie są go w stanie przecież przetestować, stąd wiele błędów. Często procedury obsługi błędów są niepoprawne, komunikaty o błędach mylące, albo program nie wraca do stanu normalnego we właściwy sposób. 69.Przetestować losowe zmiany stanów. Jeśli ma się do dyspozycji mape stanów programu, można w nią rzucać strzałkami i potem testować przejścia od strzałki do strzałki. W rozdziale 14ym „Automatyczne testowanie i narzędzia do testowania” znjadują się informacje o tym, jak zautomatyzować losowe testowanie przejść stanów.
Co szczególnie należy przetestować
Kiedy się już zidentyfikuje stany i przejścia między stanami, które chce się przetestować, można przystąpić do zdefiniowania zadań testowych.
Testowanie stanów i przejść między stanami oznacza sprawdzenie wszystkich zmiennych określających stan: informacji, wartości, funkcji itd. wiążących się z danym stanem lub zmieniających się przy przejściu od stanu do stanu. Rysunek 5.11 pokazuje przykładowo program Paint w stanie początkowym.
Rysunek 5.11 Pierwszy ekran programu Paint w stanie początkowym.
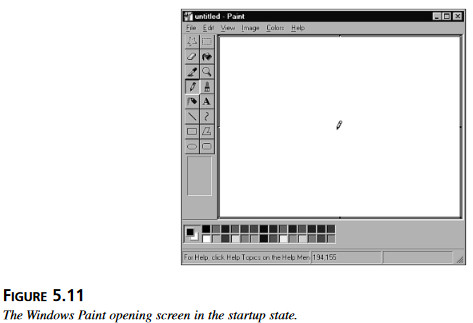
Oto lista wartości zmiennych które charkteryzują stan początkowy programu Paint: 70.Okno wygląda tak, jak na rysunku 5.11. 71.Wymiary okna są takie jak podczas poprzedniego użycia. 72.Obszar obrazu jest pusty.
73.Wyświetlone jest menu do wyboru narzędzi, koloru i pasek pokazujący status. 74.Ołówek jest wybranym narzędziem. 75.Domyślne kolory to czarny pierwszy plan i białe tło. 76.Tytuł dokumentu jest bez tytułu. Program Paint ma wiele, wiele innych zmiennych określających stan, które można by wziąć pod uwagę, ale podane przykłady powinny wyjasnić, na czym polega zdefiniowanie stanu programu. Warto pamiętać, że tak samo postępuje się identyfikując stan programu niezależnie od tego, czy opis stanu określają zmienne tak widoczne jak okno lub okno dialogowe, czy niewidoczne jak w wypadku stanów programu komunikacyjnego albo aplikacji finansowej.
Dobrze jest przedyskutować swoje przypuszczenia dotyczące stanów i przejść między nimi z autorami specyfikacji i z programistami. Można od nich uzyskać wgląd w to, co dzieje się wewnątrz programu.
Flaga sygnalizuje „brudny dokument”
Zmienne określające stan mogą być niewidoczne lub widoczne. Typowy przykład to flaga sygnalizująca „brudny dokument”.
Kiedy dokument zostaje załadowany do programu, takiego jak program do przetwarzania tekstu albo program do malowania, wewnętrzna zmienna określająca stan, zwana „flagą brudnego dokumentu” jest wyzerowana i dokument jest w stanie „czystym”. Program pozostaje w tym stanie dopóty, dopóki nie zostaną dokonane jakieś zmiany w dokumencie. Dokument można czytać i przewijać – wartość zmiennej pozostaje niezmieniona. Jak tylko jednak coś zostanie napisane albo dokument zostanie zmieniony w jakikolwiek inny sposób, program zmieni swój stan na stan „brudny”.
Jeśli chce się zamknąć lub wyjść z dokumentu w stanie czystym, odbędzie się to bez przeszkód. Jeśli dokument jest „brudny”, użytkownik otrzyma komunikat z pytaniem, czy dokument należy zapisać przed wyjściem z aplikacji.
Niektóre programy są tak wyrafinowane, że jeśli dokona się jakiejś zmiany, którą potem się odwoła i dokument powróci do stanu wyjściowego, to program powróci też do stanu „czystego”. Wyjście z programu jest wtedy możliwe bez pytania, czy chce się zapisać dokument.
Negatywne testowanie stanów
Wszystko co dotąd zostało przedyskutowane dotyczyło testowania pozytywnego. Przegląda się specyfikację, szkicuje stany programu, wypróbowuje liczne dozwolone warianty i upewnia się, że stany i przejścia między stanami działają. Drugą stroną medalu, tak samo jak przy testowaniu danych, jest sprawdzenie czy program działa też wówczas, kiedy poddać go negatywnym zadaniom testowym. Przykłady takich sytuacji to warunki wyścigu, powtórzenia, stres i obciążenie.
Wyścig i błędna synchronizacja w czasie
Większość współczesnych systemów operacyjnych, zarówno dla komputerów osobistych jak i dla sprzętu specjalnego, jest zdolna do wielozadaniowości. Wielozadaniowość oznacza że system operacyjny jest skonstruowany tak, by móc wykonywać wiele różnych procesów równolegle. Te procesy to mogą być odrębne programy użytkowe, jak arkusz kalkulacyjny lub poczta komputerowa. Mogą też być częściami tego samego programu, jak na przykład wydruk w tle, gdy jednocześnie można wpisywać nowe słowa do programu przetwarzającego tekst.
Skonstruowanie wielozadaniowego systemu operacyjnego nie jest trywialne, tak samo jak nie jest łatwo zaprojektować program użytkowy wykorzystujący wielozadaniowość. W systemie prawdziwie wielozadaniowym niczego nie można uważać za pewnik. Program musi sobie móc poradzić z przerwaniem nadchodzącym w każdym momencie, być wykonywanym jednocześnie z nieznanymi, innymi programami, oraz posługiwać się wspólnie z innymi programami dostępem do zasobów takich jak pamięć, dysk, komunikacja i inne zasoby sprzętowe.
Wszystko to prowadzi niekiedy do sytuacji zwanej wyścigiem. Polega to na tym, że kilka procesów jednocześnie „ściga” się do linii mety, jaką jest np. zawładnięcie zasobem albo zapisanie wartości w pamięci, i w konsekwencji działanie programu zależy od przypadkowej „wygranej” jednego z procesów. Mówiąc ogólnie, chodzi tu o złą synchronizację w czasie. Może się też zdarzyć, że jeden proces przerwie wykonywanie drugiego procesu w momencie, który nie był przewidziany.
Trudno jest zaplanować testowanie nakierowane na wykrycie sytuacji wyścigu1, ale dobrym początkiem jest przyjrzeć się diagramowi zmian stanów. Jakie zewnętrzne czynniki mogą przerwać każdy stan? Co stanie się, jeśli potrzebne dane nie będą gotowe na czas albo będą zmieniane przez jeden proces w momencie, kiedy drugi proces je czyta? Co będzie, jeśli dane prowadzące do dwóch różnych przejść z aktualnego stanu nadejdą jednocześnie?
1 Autor używa tutaj określenia wyścig (race condition) na oznaczenie wszelkich błędów specyficznych dla systemów czasu rzeczywistego. Jest to dość pewne uogólnienie (w rzeczywistości wyścig jest tylko jednym z wielu typów takich błędów), ale bez znaczenia o tyle, że książka i tak nie opisuje żadnych technik testowania specjalnych dla systemów czasu rzeczywistego.
Oto kilka przykładów sytuacji, które mogą doprowadzić do zaistnienia wyścigu: 77.Zapisywanie tego samego dokumentu jednocześnie przez dwa różne programy 78.Korzystanie przez różne programy ze wspólnej drukarki, portu komunikacyjnego albo innego urządzenia peryferyjnego 79.Naciskanie klawiszy albo klikanie myszą w czasie gdy aplikacja ładuje się lub właśnie zmienia stan 80.Jednoczesne zamykanie lub otwieranie dwóch instancji tego samego programu 81.Jednoczesne zapisywanie w bazie danych przez dwa różne programy
Może to wszystko wydaje się zbędnie zawiłymi testami, ale tak nie jest. Oprogramowanie musi być dostatecznie odporne na błędy, żeby poradzić sobie z takimi sytuacjami. Wiele lat temu podobne sytuacje może były niezwykłe, ale dziś użytkownicy oczekują, że programy czasu rzeczywistego będą działać poprawnie.
Powtarzanie, obciążenie i przeciążanie
Innymi rodzajami negatywnych testów stanów są powtarzanie, przeciążanie i obciążenie1. Mają one na celu wychwycenie błędów przy zmianie stanów, pojawiających się w szczególnych warunkach, których programista nie wziął pod uwagę.
Testowanie powtarzalne polega na powtarzaniu tej samej operacji w kółko na okrągło. Może to być coś tak prostego jak wielokrotne otwieranie i zamykanie programu. Można też raz po raz zapisywać i z powrotem ładować dane z pliku, albo w ogóle powtarzać wielokrotnie jakiekolwiek zadanie. Może uda się trafić na błąd już po kilku powtórkach – a może trzeba będzie tysięcy prób, żeby problem się ujawnił.
1 Pewne zamieszanie terminologiczne. Testy na obciążenie i przeciążenie zaliczają się do testów wydajności (jak – szybko, dużo itd. – program pracuje), podczas gdy testowanie stanów jest metodyką stosowaną do wybierania zadań testowych głównie do testowania funkcjonalnego (czy program wykonuje właściwe funkcje). Jedno z drugim niewiele ma wspólnego. Opisane w tym podrozdziale testy wydajności znalazły się w rozdziale o testowaniu stanów raczej przez przypadek.
Głównym celem testowania powtarzalnego jest poszukiwanie przecieków pamięci1. Często spotykany błąd pojawia się, kiedy fragment pamięci zostanie przydzielony programowi, ale nie zostanie potem uwolniony (lub nie do końca), kiedy wykorzystująca tę pamięć operacja zostanie już zakończona. W końcu, po jakimś czasie program zużyje całą dostępną pamięć. Każdy kto posługiwał się programem, który początkowo działa dobrze, ale stopniowo zaczyna działać coraz wolniej i wolniej, albo po jakimś czasie zaczyna funkcjonować niekonsekwentnie, zetknął się przypuszczalnie właśnie z problemem przecieku pamięci. Testowanie powtarzalne ma na celu znajdowanie i usunięcie tego typu błędów.
Test przeciążający polega na tym, że program zmusza się do działania w niekorzystnych warunkach – za mało pamięci, za wolny mikroprocesor, powolne modemy itd. Należy zorientować się, od jakich zewnętrznych zasobów program jest uzależniony. Testowanie przeciążające polega na ograniczeniu tych zasobów do najzupełniejszego minimum. Staramy się po prostu „wygłodzić” program, zmuszając go do pracy przy niedostatecznych zasobach. Czy to nie przypomina testowania warunków brzegowych? Jak najbardziej.
Testowanie obciążające2 jest odwrotnością testowania przeciążającego. W czasie testowania przeciążającego staramy się „wygłodzić” program; w czasie testowania obciążającego ładujemy w program tyle danych, ile tylko się da. Przykladowo, każemy programowi używać największych możliwych plików danych. Jeśli program używa urządzeń peryferyjnych, jak drukarki albo porty komunikacyjne, podłącza się tyle ile się tylko da. Testując serwer internetowy mający obsługiwać tysiące jednoczesnych sesji, należy wypróbować właśnie tysiące jednoczesnych sesji. Należy „przycisnąć” program, obsiążyć go ile się tylko da.
Nie zapominajmy, że także czas jest zmienną którą można wykorzystać do testowania obciążającego. Ważne jest, żeby przetestować działanie programu przez długi czas. Niektóre typy programów powinny móc funkcjonować latami bez konieczności ponownego włączenia.
Oczywiście w praktyce można połączyć w jeden ciąg testowanie powtarzalne, przeciążające i obciążające.
1 Ten rodzaj testowania, który autor nazywa “testowaniem powtarzalnym”, określany jest często jako analiza dynamiczna. Jej celem jest znalezienie nie tylko przecieków pamięci, ale wszelkich błędów typu niedozwolone skutki uboczne działania programu, których symptomy ujawniają się często najwyraźniej dopiero po upływie dłuższego czasu (przyp. tłumacza).
2 Testowanie przeciążające definiuje się często jako testowanie działania programu w warunkach obciążenia większego niż maksymalne dozwolone (np. test centrali telefonicznej w sytuacji, gdy wszyscy abonenci jednocześnie podniosą sluchawki). Oczywiście, tego rodzaju “wygłodzenie” programu, jakie opisuje autor, jest skutecznym sposobem symulacji przeciążenia (ściślej, wynikłego z przeciążenia braku zasobów) bez potrzeby kłopotliwego generowania prawdziwego obciążenia, ale nie jest celem samym w sobie (przyp. tłumacza).
Przy testowaniu powtarzalnym, przeciążającym i obciążającym trzeba pamiętać o dwóch sprawach: 82.Programiści i kierownicy zespołów mogą nie popierać usiłowań złamania programu w taki sposób. Będą się skarżyć, że prawdziwi użytkownicy nigdy nie będą obciążać programu aż do tego stopnia. Krótka odpowiedź brzmi: owszem, będą. Zadaniem testera jest upewnić się, czy program działa również w takich warunkach i zgłosić błędy, jeśłi nie działa1. Rozdział 18-y „Raportowanie wyników” wyjaśnia, jak najlepiej zgłaszać i opisywać znalezione błędy tak, żeby zostały potraktowane poważnie i naprawione. 83.Zamykanie i otwieranie programu milion razy jest przypuszczalnie niewykonalne, jeśli robić to ręcznie. Podobnie, niełatwo będzie znaleźć i zorganizować grupę kilku tysięcy osób, żeby jednocześnie podłączyły się do testowanej aplikacji internetowej. Rozdział 14 opisuje automatyzację testowania i zawiera wiele informacji, jak można przeprowadzać testy osiągów bez konieczności angażowania osób do ręcznego wykonania tej pracy. Inne techniki czarnej skrzynki
Pozostałe typy technik czarnej skrzynki to nie są właściwie odrębne metody, lecz raczej odmiany już opisanych technik testowania danych i testowania stanów2. Jeśli dokonało się starannej identyfikacji klas równoważności na danych programu, sporządziło szczegółową mapę stanów programu i sporządziło na ich podstawie zadania testowe, znalazło się przypuszczalnie większość błędów, jakie może znaleźć użytkownik.
Pozostały nam techniki dla znajdowania „zbłąkanych błędów”, które – zupełnie jakby były prawdziwymi, żywymi „pluskwami” – wydają się poruszać, kierowane własnym, niezależnym umysłem. Znajdowanie ich może wydawać się zadaniem nie stosującym się do zasad zdrowego rozsądku, ale chcąc znaleźć i usunąć każdy, najlepiej ukryty błąd, trzeba będzie wykazać się twórczą fantazją.
Autor:1 W zasadzie, tego rodzaju spór między testerami a programistami nie powinien mieć miejsca: te sprawy powinny być jednoznacznie rozstrzygnięte przez specyfikację wymagań. W praktyce, specyfikacje bywają notorycznie niedokładne zwłaszcza jeśli chodzi o określenie wymagań dotyczących osiągów i wówczas intuicja tesera – jak to opisuje autor – może częściowo zastąpić brakujący opis wymagań (przyp. tłumacza).
2 Istnieje wiele innych interesujących technik czarnej skrzynki (m.in. bardzo skuteczne do wychwytywania pewnych typów błędów testowanie syntaktyczne) których książka dla początkujących z konieczności nie opisuje (przyp. tłumacza).
Zachować się jak głupi użytkownik
Terminem politycznie poprawnym powinno być raczej niedoświadczony użytkownik albo nowy użytkownik, ale w rzeczywistości chodzi przecież o to samo. Wystarczy posadzić przed komputerem osobę, która programu zupełnie nie zna, a zobaczymy wkrótce jak usiłuje zrobić rzeczy, które nam do głowy nie przyszły w najśmielszych marzeniach. Będzie wprowadzać do programu dane, jakie nam nawet nie przyszły do głowy. Zmieni zdanie w połowie wykonywania zadania, wycofa się i zrobi coś innego. Przesurfuje przez stronę internetową, klikając na przyciski, na które klikać nie należy3. Znajdzie błędy, które testerzy przeoczyli zupełnie.
To może być dla testera szalenie frustrujące, obserwować kogoś zupełnie pozbawionego doświadczenia w testowaniu, kto w ciągu pięciu minut jest w stanie spowodować awarię programu, który wcześniej testowało się tygodniami. Jak on to robi? Po prostu nie stosuje się do żadnych zasad i nie robi żadnych założeń.
Warto wobec tego, konstruując zadania testowe albo badając program po raz pierwszy, spróbować wejść w skórę „głupiego użytkownika”. Spróbować odrzucić wszelkie założenia i przypuszczenia o tym, jak program powinien działać. Można spróbować sprowadzić kolegę, który nie jest w projekcie i razem z nim wymyślać szalone pomysły. Niczego nie przyjmować za pewnik. Tego typu zadania testowe dodane do specyfikacji będą stanowiły całkiem pokaźną jej część.
Szukać błędów tam, gdzie się je już raz znalazło
Są dwa powody, dla których warto szukać błędów tam, gdzie się je już wcześniej znalazło.
3 Wygoda użytkowania i intuicyjność interfejsu, na którym nowy użytkownik zrobi to wszystko, zdaje się pozostawiać wiele do życzenia… jak w rzeczywistości rzecz ma się z wieloma programami (przyp. tłumacza).
84.Jak dowiedzieliśmy się w rozdziale 3-im, im więcej błędów się znajduje, tym więcej błędów tam się jeszcze ukrywa. Jeśli znajduje się na przykład dużo błędów na górnych granicach przedziałów w różnych funkcjach oprogramowania, to warto poświęcić więcej uwagi testowaniu górnych granic przedziałów. Oczywiście, to by się zrobiło i tak, ale warto dorzucić kilka dodatkowych zadań testowych, wiedząc, że mogą okazać się skuteczne. 85.Wielu programistów naprawia tylko błąd opisany w raporcie błędu – ani więcej, ani mniej. Jeśli się napisało, że wystartowanie, zatrzymanie i ponowne wystartowanie programu 255 razy powoduje awarię, to programista przypuszczalnie to właśnie naprawi. Może istniał tam gdzieś przeciek pamięci, który programista znalazł i usunął. Kiedy dostanie się naprawiony program do ponownego przetestowania, na pewno warto zrobić dokładnie to samo – 256 razy i więcej. Może gdzieś ukrywa się jeszcze kolejny przeciek pamięci?
Posłuchać własnego doświadczenia, intuicji i… przeczuć
Nie ma lepszego sposobu żeby stać się lepszym testerem niż zbierać doświadczenie. Nie ma lepszej metody nauczenia się niż testując, i nie ma skuteczniejszej lekcji niż pierwszy telefon od klienta, co znalazł błąd w programie, który właśnie skończyło się testować.
Nie można nauczyć doświadczenia i intuicji, trzeba je zdobywać samemu. Można zastosować opisane dotąd techniki i przegapić poważne błędy, taka jest natura tej pracy. Zdobywając doświadczenie zawodowe, uczymy się różnych rodzajów i różnych wielkości produktów, zbieramy rozmaite wskazówki, które pokierują nas w stronę trudnych do znalezienia błędów. Po jakimś czasie jest się w stanie zasiąść do testowania nowego kawałka oprogramowania i szybko znajdować błędy, których inni by nie zauważyli.
Warto zapisywać, co działa, a co nie, próbować różnych sposobów. Jeśli coś wygląda podejrzanie, zawsze warto się temu przypatrzeć dokładniej. Warto posłuchać własnych przeczuć, dopóki nie okażą się fałszywe.
Doświadczenie to nazwa, jaką ludzie nadają swoim pomyłkom.
Oscar Wilde Podsumowanie
To był długi rozdział. Dynamiczne testowanie metodami czarnej skrzynki jest obszerną dziedziną. Dla nowych testerów, to mógł być najważniejszy rozdział z całej książki. Prawdobodobnie w czasie wywiadu u pracodawcy albo w pierwszym dniu pracy otrzyma się polecenie, żeby przetestwoać program. Stosując techniki z tego rozdziału, będzie można od razu znajdować błędy.
Nie należy jednak przypuszczać, że to już wszystko, co testowanie oprogramowania ma do zaoferowania. Gdyby tak było, można by przestać czytać i zlekceważyć pozostałe rozdziały książki. Testowanie dynamiczne metodami czarnej skrzynki to dopiero początek. Test oprogramowania wymaga więcej wiedzy, a my dopierośmy zaczęli ją zdobywać.
Dwa kolejne rozdziały wprowadzają do testowania w sytuacji, kiedy ma się dostęp do kodu i można zobaczyć, jak program działa i co robi na najniższym poziomie. Poznane techniki czarnej skrzynki nadal są przydatne, ale można je uzupełnić nowymi technikami, które pozwolą stać się jeszcze skuteczniejszymi testerami oprogramowania. Pytania
Pytania mają na celu ułatwienie zrozumienia. W aneksie A „Odpowiedzi do pytań” znajdują się prawidłowe rozwiązania – ale nie należy ściągać! 1.Prawda czy fałsz: czy da się wykonywać dynamiczne testowanie metodami czarnej skrzynki bez specyfikacji produktu albo specyfikacji wymagań? 2.Kiedy testuje się zdolność programu do robienia wydruków, jakie ogólne, negatywne zadania testowe są właściwe? 3.Wystartuj Notatnik Windows i wybierz funkcję Drukuj z menu Plik. Pojawia się wtedy okno dialogowe pokazane na rysunku 5.12. Jakie warunki brzegowe istnieją dla funkcji Zakres w dolnym, lewym rogu okna?
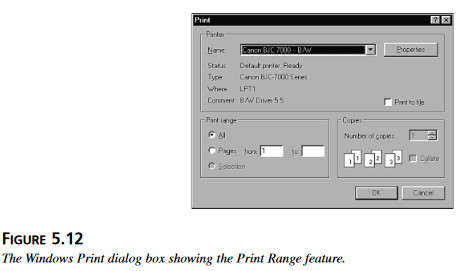 Rysunek 5.12 Okno dialogowe funkcji Drukuj z funkcją wyboru zakresu. 4. Mamy pole do wprowadzania 10-cyfrowego kodu pocztowego, jak na rysunku 5.13. Jakie klasy równoważności można zastosować do jego testowania?
Rysunek 5.12 Okno dialogowe funkcji Drukuj z funkcją wyboru zakresu. 4. Mamy pole do wprowadzania 10-cyfrowego kodu pocztowego, jak na rysunku 5.13. Jakie klasy równoważności można zastosować do jego testowania?

Rysunek 5.13 Przykładowe pole do wprowadzania 5-cyfrowego kodu pocztowego. 5. Prawda czy fałsz: przejście wszystkich stanów programu gwarantuje również, że przeszło się wszystkie przejścia między nimi. 6. Istnieje wiele sposobów rysowania diagramów przejścia stanów, ale każdy z nich pokazuje trzy rzeczy. Jakie? 7. Podaj niektóre z wartości zmiennych w stanie początkowym Kalkulatora Windowsów. 8. Co robi się z programem, chcąc odkryć błędy w synchronizacji w czasie (wyścig)? 9. Prawda czy fałsz: jednoczesne wykonywanie testowania na obciążenie i na przeciążenie jest niedopuszczalne.