rozdział 10
08 września 2019, 22:02
Rozdział 10 Testowanie różnych wersji językowych
W TYM ROZDZIALE Aby słowa i rysunki miały sens Kwestie tłumaczenia Kwestie ulokalnienia Zagadnienia konfiguracji i kompatybilności Jak wiele trzeba testować?
Si tu eres fluente en mas de un idioma y competente en provando programas de computadora, tu tienes una habilidad muy decenda en el mercado.
Wenn Się eine zuverläßig Software Prüferin sind, und fließend eine fremdsprache, ausser English, sprechen können, dann können Się gut verdienen.
Przetłumaczone z grubsza z hiszpńskiego i niemiećkiego, powyższe zdania znaczą: Ten kto jest doświadczonym testerem oprogramowania i zna dobrze inny język oprócz angielskiego, może się spodziewać wysokich zarobków1.
Wiele programów wypuszcza się dzisiaj na cały świat, nie tylko na rynek jednego kraju albo tylko w jednym języku. Micorsoft dostarczał Windows 98 z obsługą dla 73 różnych języków, od Afrikaans przez węgierski do wietnamskiego. Większość innych firm produkujących oprogramowanie postępuje podobnie, zdając sobie sprawę, że angielskojęzyczny rynek amerykański to ledwo połowa potencjalnych klientów. Projektowanie i testowanie oprogramowania pod kątem sprzedaży na całym świecie przynosi konkretne zyski.
W tym rozdziale poznamy wymagania wobec testowania programów pisanych dla wileu krajów i języków. Na pierwszy rzut oka wydaje się to nieskomplikowane, ale rzeczywistość jest inna i dowiemy się, dlaczego.
Główne punkty tego rodziału to: 50.Czemu samo tłumaczenie nie wystarcza 51.Jak zmiana języka wpływa na słowa i na cały tekst 52.Czemu piłka nożna i telefon są ważne 53.Zagadnienia konfiguracji i kompatybilności
1 To zdanie, jak i cały rozdział, napisany jest z wyraźnie amerykańskiej perspektywy. W niczym nie zmienia to jego aktualności, choć oczywiśćie polscy producenci oprogramowania rzadziej niż amerykańscy wytwarzają programy przenaczone do użytku wielojęzycznego (przyp. tłumacza).
54.Jak wiele pracy wymaga testowanie pod kątem innego języka Aby słowa i rysunki miały sens
Każdy pewnie kiedyś czytał instrukcję obsługi zabawki albo urządzenia, źle – dosłownie – przetłumaczoną z innego języka. „Przełóż trzpień numer pięć przez zieloną kratkę i dokręć nie luźno żadną nakrętke.” Jasne?
To jest przykład złego tłumaczenia, i tak właśnie oprogramowanie może wyglądać, kiedy nie dość wysiłku włożyło się w przygotowanie wersji innych niż oryginalna. Łatwo jest przetłumaczyć tekst słowo po słowie, ale zachowanie znaczenia wymaga więcej pracy i uwagi.
Dobry tłumacz potrafi to właśnie osiągnąć. Kto mówi płynnie w obu językach, potrafi sporządzić tłumaczenie równie poprawne i zrozumiałe jak oryginał. Niestety, w przemyśle informatycznym samo dobre tłumaczenie nie zawsze wystarcza.
Weźmy jako przykład język hiszpański. To chyba prosta sprawa przetłumaczyć tekst angielski na hiszpański, prawda? Dobrze, ale który hiszpański? Hiszpański z Hiszpanii? A co z hiszpańskim z Kostaryki, z Peru, z Dominikany? Wszędzie tam mówi się po hiszpańsku, ale są to odmiany na tyle różne, że program napisany pod kątem jednego może być źle przyjęty przez inne. Nawet angielski ma podobne kłopoty. Istniej nie tylko angielski amerykański, ale kanadyjski, australijski i brytyjski. W oczach amerykańskiego użytkownika słowa colour albo neighbour wyglądają dziwacznie1.
Trzeba wziąć pod uwagę, oprócz samego języka, również tak zwaną specyfikę regionalną: kraj albo region, z którego pochodzi użytkownik. Proces ten naywa się ulokalnieniem: dostosowywanie oprogramowania do lokalnej specyfiki, dialektu, obyczajów i kultury. Testowanie tak przetworzonego oprogramowania nazywa się testowaniem ulokalnienia. Kwestie tłumaczenia
Chociaż tłumaczenie jest tyko częścią całego procesu ulokalniania, jest szczeglnie ważne z punktu widzenia testowania. Najprostszym problemem jest – jak można przetestować coś posługującego się innym językiem? Cóż, któryś z testerów musi w tym celu mieć choćiaż średnią znajomość tego języka aby móc przemieszczać się w programie, czytać i rozumieć wyświetlane przez program teksty infromacyjne i pisać komnedy niezbędne do uruchomienia programu. Może jest wobec tego czas najwyższy, aby zapisać się na kurs języka słoweńskiego, o którym się od dawna marzyło?
1 Brytyjska i amerykańska ortografia różnią się w tym miejscu: brytyjskiemu colour i neighbour odpowiada amerykańskie color i neighbor (przyp. tłumacza).
Ważne by choć jedna osoba w zespole testującym znała choć trochę język, który się testuje1. Oczywiście, jeśli program będzie mógł obsługiwać 32 różne języki, może to być trudno osiągnąć. Rozwiązaniem jest przekazanie tego zadania firmie specjalizującej się w testowaniu ulokalnienia. Liczne takie firmy na całym świecie są w stanie podjąć się testowania niemal we wszystkicj językach. Aby znaleźć więcej wiadomości na ten temat, wystarczy przeszukiwać zwrotu „localization testing”2 na Internecie.
Nie musi się wymagać, aby każdy w zespole znał język, na który dokonuje się ulokalniania. Przypuszcalnie wystarczy jedna tylko osoba. Wiele rzeczy można sprawdzić nie znając znaczenia słów. Na pewno pomocna jest pewna znajomość, ale daje się sporo przetestować nie mówiąc płynnie w danym języku.
Rozszerzanie tekstu
Najprostszym przykładem kłopotu z tłumaczeniami jest tak zwane rozszerzanie tekstu. Chociaż język angielski może się czasem wydawać rozwlekły, okazuje się, że tłumacząc angielski na inne języki zwykle potrzeba więcej liter dla wyrażenia tej samej rzeczy. Rysunek 10.1 pokazuje jak wielkość przycisku rośnie, aby zmieścił się na nim tekst dwóch często spotykanych określeń komputerowych. Dobrym oszacowaniem jest spodziewać się do 100-procentowego wzrostu wielkości poszczególnych słów – na przykład na przycisku. Można się spodziewać 50-procentowego wzrostu rozmiarów zdań i krótkich akapitów – typowych zwrotów, jakie znajdują się w oknach dialogowych i w komunikatach o awariach.
Rysunek 10.1 Słowa Minimize (minimalizuj) i Maximize (maksymalizuj) mogą mieć różną wielkość w różnych językach, co może zmusić do przekonstruowania interfejsu użytkownika, aby stworzyć dla nich miejsce.
1 Najlepiej, oczywiście, aby wszyscy znali ten język doskonale. Istotne dla krajów, które więcej oprogramowania importują niż eksportują… (przyp. tłumacza).
2 W wersji brytyjskiej będzie to “localisation”, nie “localization” (przyp. tłumacza).
Z powodu zjawiska rozszerzenia, należy szczególnie staranie przetestować te części programu, które mogą ulec zmianie z powodu rozszerzonego tekstu. Warto zwrócić uwagę na tekst, gdzie słowa nie są przenoszone poprawnie do następnej linijki, skracane lub nieprawidłowo dzielone. Może się to zdarzyć gdziekolwiek – w każdym punkcie ekranu, w oknach, na przyciskach itp. Szuka się też sytuacji, gdzie tekst wprawdzie znalazł miejsce do rozszerzenia się, ale przy okazji usunął z ekranu coś innego.
Może się też zdarzyć, że dłuższy tekst spowoduje poważną awarię programu albo nawet awarię całego systemu. Programista mógł był przydzielić dość wewnętrznej pamięci na komunikaty angielskie, ale nie na dłuższe, przetłumaczone ciągi znaków. Wersja angielska będzie działać poprawnie, ale niemiećka ulegnie awarii, kiedy pojawi się jakiś komunikat. Tester stosujący metody szklanej skrzynki może znaleźć ten błąd nie znając ani słowa po niemiećku.
ASCII, DBCS i Unicode
W rozdziale 5-ym „Testowanie oprogramowania z klapkami na oczach” krótko został omówiony zbiór znaków ASCII. ASCII zawiera tylko 256 znaków – zbyt mało, aby zmieścić wszelkie możliwe znaki we wszystkich językach. Kiedy zaczęto wytwarzać oprogramowanie w wielu różnych językach, pojawiła się potrzeba nowych rozwiązań, aby ominąć to ograniczenie. Metoda popularna w czasach MS DOS-u, ale wciąż jeszcze stosowana, nazywana była techniką stron kodowych. Strona kodowa to jakby zastępcza tabela ASCII, z różnymi kodami dla różnych języków. Program wykonywany w Quebec`u na francuskim PC mógł załadować i używać stronę zawierającą francuskie znaki. Rosyjski używa innej strony kodowej dla znaków cyrylicy i tak dalej.
Takie rozwiązanie działa, choć dość niezdarnie, dla języków mających mniej niż 256 znaków. Jednak japoński, chiński i inne języki mające tysiące znaków stwarzają nowe kłopoty. System zwany DBCS (Double-Byte Character Set – zbiór znaków dwubajtowych) stosowany jest przez niektóre programy. Użycie dwóch zamiast jednego bajtu umożliwia zdefiniowanie do 65356 różnych znaków.
Strony kodowe i DBCS często wystarczają, ale jest z nimi kilka problemów. Najważniejszy to kwestia kompatybilności. Jeśli załadować hebrajski dokument na niemiećki komputer z angielskim programem do przetwarzania tekstu, wynika z tego groch z kapustą. Jeśli nie ma się właściwych stron kodowych ani przekładu z jednych na drugie, znaków nie daje się odtworzyć poprawnie.
Wyjściem z tego całego bałaganu jest standard Unicode.
Unicode przypisuje jedną, niepowtarzalną liczbę każdemu znakowi, niezależnie od plaformy, niezależnie od programu,
niezależnie od języka.
„Co to jest Unicode?” z witryny Konsorcjum Unicode www.unicode.org
Unicode jest międzynarodowym standardem, popieranym przez większe firmy produkujące oprogramowanie, przez producentów sprzętu i przez inne organizacje zajmujące się standaryzacją, dzięki czemu stale się rozpowszechnia. Stosuje go większość popularnych aplikacji. Rysunek 10.2 pokazuje jeden z wielu dostępnych zestawów znaków. Jeśli oczekuje się, że program – choćby w przyszłości – będzie ulokalniony, projekt powiniem natychmiast rozstać się ze „starym, dobrym ASCII” i przestawić na Unicode - i w ten sposób oszczędzić sobie czasu, pracy i awarii.
Rysunek 10.2 Okno dialogowe w programie Windows Word 2000 pokazuje wykorzystanie standardu Unicode.
Gorące klawisze i skróty
Po angielsku, nazwa brzmi Search. Po polsku, Szukaj. Po francusku, Réchercher. Jeśli gorący klawisz wybierający funkcję Szukaj w wersji angielskiej jest Alt-S, to w wersji francuskiej należałoby go zmienić na Alt +R.
W ulokalnionych wersjach oprogramowania trzeba przetestować czy wszystkie gorące klawisze i skróty działają prawidłowo i czy nie są zbyt trudne – na przykład wymagają naciśnięcia trzeciego klawisza. I trzeba pamiętać, by sprawdzić, czy angielskie gorące klawisze zostały poprawnie wyłączone.
Rozszerzone znaki
Często spotykanym problemem w ulokalnionych – i nie tylko – wersjach oprogramowania, jest użycie rozszerzonych znaków. W odniesięniu do starożytnej tabeli ASCII, rozszerzone znaki to te, które są poza zwykłymi literami angielskigo alfabetu A-Z i a-z, na przkład é w José albo ñ w el Niño. Jeśli program jest napisany prawidłowo i posługuje się Unicodem albo jeśli poprawnie zarządza stronami kodowymi lub DBCS, nie powinno być kłopotu, ale tester nigdy niczego nie powiniem zakładać, więc warto sprawdzić.
Błędów naeży przede wszystkim szukać wszędzie tam, gdzie program przyjmuje znaki albo produkuje dane wyjściowe. W tych miejscach trzeba użyć rozszerzonych znaków i sprawdzić, czy funkcjonują równie dobrze jak zwykłe znaki. Okna dialogowe, dialogi do wlogowania się i wszelkie inne pola tekstowe powinny być sprawdzone. Czy da się wysyłać i przyjmować rozszerzone znaki przez modem? Czy można je stosować w nazwach plików lub mieć je w plikach? czy zostaną poprawnie wydrukowane? Co się stanie jeśli je wycinać, kopiować i wklejać między testowanym programem i innymi aplikacjami?
Najprostszy sposób, żeby nie zapomnieć o przetestowaniu rozszerzonych znaków, to doadać je do używanej klasy równoważności zawierającej wszystkie używane przy testowaniu, zwykłe znaki. Oprócz tych często powodujących awarie znaków na krańcach tabeli ASCII, warto dorzucić Æ, Ø, ß, Ę, Ź…
Obliczenia na znakach
Dodatkowy kłopot z rozszerzonymi znakami powstaje wtedy, kiedy oprogramowanie używa znaków do obliczeń. Dwa przykłady to sortowanie teksów i przekształcanie na małe lub na duże litery.
Czy nasze oprogramowanie potrafi wytwarzać posortowane listy wyrazów? Na przykład w liście dających się wybierać pozycji takich jak nazwy plików lub adresy Internetowe? Jeśli tak, to jak należałoby posortować następującą listę słów?
Kopiëren Reiste Ärmlich Arg Reiskorn résumé Reißaus kopieën reiten Reisschnaps reißen resume
Testując oprogramowanie przeznaczone do sprzedzży na rynki azjatyckie, trzeba sobie zdawać sprawę, że kierunek sortowania opiera się na kolejności ruchów pędzla. Niniejsza lista miałoby przypuszczalnie zupełnie inna kolejność, gdyby była napisana po chińsku. Należy sprawdzić, jakie reguły sortowania obowiązują w języku, który się testuje, i skonstruować testy specjalnie nastawione na kontrolę porządku sortowania.
Drugi rejon, gdzie załamują się obliczenia dokonywane na rozszerzonych znakach, to przekształcanie na małe i na duże litery. Problem bierze się stąd, że „sztuczką”, której wielu programistów uczy się jeszcze w szkole, to dodanie lub odjęcie wartości 32 do wartości ASCII danego znaku, by przekształcić go w małą lub dużą literę. Dodając np. 32 do wartości ASCII A otrzymuje się wartość ASCII a. Niestety, ta reguła nie działa dla rozszerzonych znaków. Stosując tę technikę wobec rozszerzonego zbioru znaków Apple Macintosha, przeksztalciłoby się np. Ñ (ASCII 132) w § (ASCII 164), zamiast w ñ (ASCII 150) – nie to o co chodziło.
Sortowanie i przekształcanie znaków w duże i małe to tylko jeden z wielu przykładów. Warto przyjrzeć się uważnie oprogramowniu, którym się posługujemy, aby zidentyfikowć inne sytuacje, gdzie obliczenia wykonywane były wprost na słowach albo na literach. Może programy kontrolujące pisownię?
Czytanie z lewa na prawo i z prawa na lewo
Trudnym orzechem do zgryzienia jest to, że wiele języków, np. hebrajski i arabski, czytają od prawej do lewej, nie zaś od lewej do prawej. Oznacza to, że cały interfejs użytkownika trzeba przerobić w jego lustrzane odbicie.
Na szczęście, większość systemów operacyjnych zawiera wspomaganie dla tych języków. Bez tego, byłoby to zadanie niemal niewykonalne. Tak czy owak, nie jest to już samo proste tłumaczenie. Wkorzystanie funkcji systemowych do wykonania tego przekształcenia wymaga sporej ilości programownaia. Z punktu widzenia testowania, bezpieczniej będzie potraktować to jako zupełnie nowy produkt, nie tylko jako ulokalnianie.
Teksty w grafice
Kolejne problemy pojawiają się, kiedy teksty używane są w grafice. Na rysunku 10.3 znajduje się kilka przykładów.
Rysunek 10.3 Word 2000 zawiera przykłady trudnego do przytłumaczenia tekstu w formie map bitowych.
Ikony na rysunku 10.3 są standardowe dla wybrania Tłustego druku, Kursywy, Podkreśleń oraz Koloru czcionki. Ponieważ te ikony zawierają litery B, I, U i A, nie znaczą nic dla kogoś z Japonii, kto nie zna angielskiego. Można domyślić się znaczenia na podstawie wyglądu – B jest trochę grubsze, I – pochylone, U – podskreślone, ale oprogramowanie nie powinno być zagadką.
Skutkiem tego, ulokalnienie oprogramowania często oznacza, że trzeba wymienić wszystkie ikony. Kidy ikon jest dużo, ulokalnienie może się stać zbyt kosztowne. Należy szukać tych błędów wcześnie w procesię wytwarzania i nie pozwolić, by prześlizgnęły się aż do końca.
Tekst należy przechowywać z dala od kodu
Ostatnim z zagadnień związanych z problemtyką tłumaczeń to kwestia „szklanoskrzynkowa” – trzymanie tekstów w innym mijescu niż kod. Oznacza to, że wszelkie ciągi znaków, komunikaty o błędach, dosłownie wszytko co powinno być tłumaczone, należy przechowywać w osobnych plikach niezależnych od kodu źródłowego. Nie powinno się nigdy znaleźć linijki kodu jak ta: Print „Hello World” Większość osoób zajmujących się lokalizacją nie jest programistami – i nie potrzebuje. Zmuszanie ich do modyfikowania – w ramach tłumaczenia – kodu źródłowego jest ryzykowne i mało wydajne. To, co powinno zostać przez nich zmienione, to zwykły plik tekstowy, zwany plikiem zasobów, zawierający wszystkie komunikaty wyświetlane przez oprogramownanie. Kiedy oprogramowanie działa, wskazuje teksty z pliku, nie wiedząc ani nie dbając o ich treść. Komunikat po angielsku czy po holendersku zostana tak samo wyświetlone.
Tak więc jest ważnym zadaniem testerów wykonujących testy metodami szklanej skrzynki, by przeszukali kod źródłowy, żeby znaleźć ukryte wbudowane ciągi znaków, których zapomniano umieścić na pliku zasobów. Mogłoby to spowodować spore zamieszanie, gdyby ważny komunikat a hiszpańskim programie pojawił się nagle po angielsku.
Innym objawem tego problemu są teksty komunikatów dynamicznie generowane przez kod. Na przykład, kawałki tekstu mogą być połączone w dłuższy komunikat. Kod mógłby na przykład mieć trzy ciągi znaków: 1.„Nacisnąłeś klawisz „ 2.zmienna typu ciąg znaków zawierająca nazwę wlaśnie nacisniętego klawisza, 3.„ w ostatniej chwili!”.
łączone potem w całość, aby stworzyć komunikat. Jeśli zmienny ciąg znaków będzie miał wartość „zatrzymać reaktor atomowy”, komunikat będzie brzmiał:
Nacisnąłeś klawisz zatrzymać reaktor atomowy w ostatniej chwili!
Trudność polega na tym, że nie wszystkie języki mają tę samą kolejność wyrazów w zdaniu. Chociaż ten tekst złożył się ładnie w całość po polsku, byłby bez sensu gdyby go dosłownie przetłumaczyć na chiński albo nawet niemiećki. Nie wolno pozwolić na ciągi znaków w kodzie i nie wolno, by program automatycznie łączył ciągi znaków w dłuższe komunikaty. Kwestie ulokalnienia
Jak już zostało powiedziane, trodności tłumaczenia to dopiero połowa kłopotu. Teksty daję się zwykle łatwo przetłumaczyć, nawet uwzględniając różne znaki i długości ciągów znaków. Dodatkowe trudności pojawiają się, kiedy chce się całe oprogramowanie dostosować do zagranicznego rynku.
Przypomnienie pojęć z rozdziału 3-ego: precyzja, trafność, niezawodność i jakość.
Oprogramowanie dobrze porzetłumaczone i dobrze przetestowane będzie precyzyjne i niezawodne, ale zapewne nietrafne i nie mające wysokiej jakości. Może wyglądać i działać świetnie, dać się łatwo odczytywać i nigdy nie ulegać awarii, ale dla użytkownika z innego kręgu kulturowego może po prostu wydawać się jakieś nie na miejscu. Dopiero dokonanie ulokalnienia produktu pozwoli na osiągnięcie pełnego dostosowania.
Zawartość
Co można by pomyśleć o nowej encyklopedii wydanej na amerykański rynek, gdyby miała zawartość pokazaną na rysunku 10.4?
Piłka nożna Nasza królowa
Budka telefoniczna
Jeździmy zawsze po lewej stronie
Rysunek 10.4 Te przykłady wyglądałyby dziwnie w encyklopedii na rynek amerykański.
W Stanach Zjednoczonych, piłka nożna to nie to samo co futbol!1 Nie jeździ się po lewej stronie. To, co nie obowiązuje w jednym kraju, obowiązuje w drugim! Testując produkt podlegający ulokalnieniu, trzeba starannie przejrzeć jego zawartość, aby upewnić się, że pasuje do obszaru kulturowego, gdzie ma być stosowany.
1 Football to w USA “futbol amerykański”, a soccer to nasza europejska piłka nożna (przyp. tłumacza).
Dotyczy to również wszystkich innych – oprócz kodu – składników produktu informatycznego (zob. rozdział 2-i „Proces wytwarzania oprogramowania”). Poniższa lista zawiera różne elementy produktu, które należy dokładnie zbadać opd kątem ulokalnienia. To nie jest lista wyczerpująca – składniki zależą od rodzaju produktu. Warto pomyśleć, jakie jeszcze inne składniki mogą sprawiać kłopoty, jeśli wysłać je do innego kraju.
Przykłady dokumentacji Ikony Obrazki Dźwięki Wideo Pliki pomocnicze Mapy z kontrowersyjnymi granicami Materiały marketingowe Opakowanie Połączenia internetowe
Za długi nos
W 1993 roku Microsoft wypuścił dwa produkty dla dzieci, zwane Pomysłowy Pisarz i Wspaniały Artysta1. W tych programach występowała postać imieniem McZee, mająca dzieciom pomagać w posługiwaniu się nimi. Wiele trudu włożono w zaprojektowanie McZee, w wybór jego wyglądu, koloru, manieryzmów, osobowości i tak dalej. Wyszedł z tego dość dziwnie wyglądający facet z wystającymi zębami, ciemnopurpurową skórą i dużym nosem.
Kiedy sporo pracy włożono już w animację postaci McZee, telefon zadzwonił w jednym z zagranicznych biur Microsoftu. Otrzymano tam właśnie wstępną wersję programu i po analizie uznano, że była nie do przyjęcia. Powód: McZee miał za długi nos. W tamtejszej kulturze, ludzie z długimi nosami byli rzadkością i – słusznie czy nie – długi nos kojarzył się z mnoóstwem negatywnych stereotypów. Stwierdzono, że produkt nie będzie się w tej postaci sprzedawał.
Storzenie dwóch różnych postaci McZee, każdej na inny rynek, byłoby zbyt kosztowne, więc wyrzucono całą pracę dotąd włożoną, a McZee rozbił sobie nos o pierwszą poważną przeszkodę.
Wypływa stąd nauka, że to treść oprogramowania – czy będzie nią tekst, grafika, dźwięki czy coś innego – ma kluczowe znaczenie dla ulokalniania. Pod tym właśnie kątem należy analizować zawartość programu, a tester – o ile nie ma doświadczenia z lokalnym kręgiem kulturowym – musi mieć do dyspozycji eksperta, który się na niej dobrze zna.
Formaty danych
1 Creative Writer i Fine Artist (przyp. tłumacza).
Różne kraje stosuja różne formaty zapisywania jednostek waluty, czasu i innych wymiarów. Tak jak i z zawartością, nie chodzi tu o samo tłumaczenie, lecz o ulokalnienie. Amerykański program do składu komputerowego, posługujący się calami, nie wystarczy tylko prztłumaczyć na centymetry. Trzeba dokonać zmian w programie we wzorach obliczeń, siatce współrzędnych i tak dalej.
Tabela 10.1 Formaty danych dla różnych krajów Jednostka Możliwe wartości Miary Metryczne lub angielskie Liczby Przecinek lub kropka dziesięta; sposoby umieszczania znaku ujemnego; użycie znaku # na oznaczenie liczby Waluta Różne symbole i gdzie je się umieszcza Data Klejność dnia, miesiąca, roku; znaki oddzielające; zera na początku; długi i krótki format daty Godzina 12-godzinny lub 24-godzinny, znaki oddzielające Kalendarz Różne kalendarze i dni początkowe (miesiąca, tygodnia itp) Adresowanie Kolejność pozycji; użycie kodu pocztowego Numery telefonów Nawiasy, myślniki lub inne znaki oddzielające części numeru od siebie Formaty papieru Różne formaty papieru i kopert
Na szczęście, większość systemów operacyjnych przeznaczonych do użytku w rożnych krajach zawiera gotowe formaty tych rodzajów danych dostosowane do różnych krajów. Rysunek 10.5 pokazuje przykład z Windows 98. Korzystanie z tego wbudowanego wspomnagania ułatwia programistom ulokalnianie programów, ale nie zastępuje myślenia.
Sposób wyświetlania daty nie wpływa na to, jaki format ma data wewnątrz w programie. Na przykład, data może mieć krótki format ddmm-rr. Nie oznacza to, że wewnętrzna reprezentacja daty jest tylko dwucyfrowa (i zawiea w sobie błąd roku dwutysięcznego). W tym wypadku ustawienie oznacza jedynie, że 2 cyfry są wyświetlane. System operacyjny posługuje się czterema cyframi dziesiętnymi do wykonywania obliczeń, o czym warto dodatkowo pamiętać przy testowaniu.
Rysunek 10.5 W Windows 98, opcje Ustawień Lokalnych pozwalają użytkownikom wybrać sposób wyświetlania liczb, waluty, godzin i dat.
Testując oprogramowanie dostosowane do danego kraju, trzeba dobrze znać jednostki miar, których się w nim używa. Aby właściwie przetestować oprogramowanie, trzeba będzie skonstruować nowe klasy równoważności, dostosowane do nowego rodzaju danych. Zagadnienia konfiguracji i kompatybilności
Kwiestie testowania konfiguracji i kompatybilności, omówione w rozdziałach 8-ym i 9-ym, stosują się w pełni do testowania ulokalnionych wersji oprogramowania. Problemy, które pojawiają się, gdy oprogramowanie współdziała z różnym sprzętem i z innymi programami, mogą nasilić się w nowych kombinacjach. Testowanie tego nie będzie koniecznie trudniejsze, może tylko trochę bardziej pracochłonne. Dodatkowym kłopotem może być dostęp do zagranicznych weresji sprzętu i programów, z którymi testowanie trzeba przeprowadzić.
Międzynarodowe konfiguracje platform
Windows 98 obsługije 73 różne języki i 66 różnych układów klawiatury. Realizuje się to poprzez dialog Właściwości Klawiatury w Panelu Sterującym. Rozwijana lista języków zaczyna się od Afrikaans, a konczy na ukraińskim i zawiera dziewięć różnych wersji angielskigo: amerykańską, australijską, brytyjską, kanadyjską, karaibską, irlandzką, z Jamajki, nowozelandzką i południowoafrykańską. Jest tam też pięć różńych dialektów niemieckich i dwadziścia hiszpańskich.
Rysunek 10.6 Windows 98 obsługuje użycie rożnych układów klawiatury i rożnych języków poprzez okno dialogowe Właściwości Klawiatury.
Rysunek 10.7 pokazuje przykłady trzech różnych układów klawiatury przeznaczonych dla różnych krajów. Zauważmy, że każda klawiatura ma klawisze ze znakami danego języka, ale również znaki angielskie. Jest to ddość powszechne, gdyż angielski jest powszechnie znany w wielu krajach, a taki układ pozwala na używanie zarówno oprogramowania lokalnego jak i angielskigo.
Klawiatury to sprzęt najbardziej zależny od języka, ale zaleznie od tego, co się testuje, inne elementy sprzętu też mogą być zależne. Na przykład drukarki muszą poprawnie drukować wszystkie znaki, które oprogramowanie im wysyła, i umieć sformatować dane wyjściowe do różnych formatów papieru w różnych krajach. Jeśli oprogramowanie używa modemu, mogą pojawić się zagadnienia związane z jakością linii telefonicznych lub z różnicami w protokołach telekomunikacyjnych. Każde urządzenie peryfyeryjne pracujące z testowanym oprogramowaniem trzeba wziąć pod uwagę, planując ewentualne zależności od języka i kraju zastosowania.
Konstruując klasy równoważności, trzeba pamiętać, żeby wziąć pod uwagę różne kombinację oprogramowania i sprzętu, które wchodzą w skład platformy. Dotyczy to zarówno sprzętu, programów obsługi i systemu operacyjnego. Posługiwanie się francuską drukarką na Macintosh‘u, z brytyjskim systemem operacyjnym i niemiecką wersją językową testowanego programu może być jak najbardzij dozwoloną konfiguracją!
Rysunek 10.7 Arabska, francuska i rosyjska klawiatura zawiera znaki specyficzne dla danego języka. Za zezwoleniem Fingertip Software, Inc. (www.fingertip.com).
Kompatybilność danych
Tak samo jak testowanie konfiguracji, również testowanie kompatybilności nabiera nowego sensu, kiedy wziąć pod uwagę potrzeby ulokalniania. Rysunek 10.8 pokazuje, jak bardzo złożone może zrobić się przeniesienie danych z jednej aplikacji do innej. Na przykład, nimiecka aplikacja stosująca metryczne jednostki miary i rozszerzony zbiór znaków, może przenieść dane do innej, francuskiej aplikacji zapisując i następnie łądując z dysku, albo posługując się funkcjami wytnij-wklej. Aplikacja francuska może z kolei wyeksportować dane, które jakaś angielska aplikacja może importować. Program angielski, posługujący się brytyjskimi jednostkami miary i nierozszerzonym zestawem znaków, może to wszystko z powrotem przenieść do niemieckiego programu.
Rysunek 10.8 Testowanie kompatybilności danych różnych ulokalnionych wersji programu może być mocno skomplikowane.
W czasie tego przesyłania danych w kółko, przy przekładaniu jednostek miar i rozszerzonych znaków, jest wiele miejsc, gdzie mogą ukrywać się błędy. Niektóre z nich mogły powstać w wyniku błędnych decyzji konstrukcyjnych. Na przykład, co ma się stać z danymi przenoszonymi z jednego do drugiego programu, jeśli musi zostać przy tym zmieniony format? Czy należy zmianę przeprowadzić automatycznie, czy powinno się zapytać użytkownika? Czy należy wyświetlić komunikat o błędzie, czy też tylko przenieść dane i zmienić jednostki miary?
Zanim można zacząć testować kompatybilność ulokalnionego oprogramowania, trzeba mieć odpowiedzi na powyższe pytania. Kiedy już ma się te odpowiedzi, testuje się tak samo jak dawniej – tyle tylko że w klasach równoważności będzie więcej elementów. Jak wiele trzeba testować?
Ważną decyzją, jaką trzeba podjąć przed przystąpieniem do testowania wersji lokalnych programu, jest ile trzeba będzie testować? Jeśli testowanie oryginalnej wersji amerykańskiej zajęło sześć miesięcy, czy testowanie ulokalnionej wersji francuskiej też powinno zająć sześć miesięcy? Czy może jeszcze dłużej, skoro pojawiły się nowe zagadnienia dotyczące konfiguracji i kompatybilności?1
Tę niełatwą decyzję można uprościć do dwóch podstawowych pytań: 55.Czy od początku planowano dokonanie ulokalnienia oprogramowania? 56.Czy w celu dokonania ulokalnienia trzeba było dokonywać zmian w kodzie programu?
Jeśli dostosowanie programu do różnych wersji lokalnych i językowych było planowane od początku, ryzyko pojawienia się wielu błędów i potrzeba rozbudowanego testowania są znacznie mniejsze. Jeśli jednak program był napisany z początku specjalnie po angielsku pod kątem rynku amerykańskiego, a decyzję o dostosowaniu do innego języka podjęto dopiero poźniej, będzie chyba najlepiej potraktować to oprogramowanie jak zupełnie nową wersję wymagającą pełnego testowania.
Drugie pytanie dotyvczy tego, jakich zmian trzeba było dokonać w całym produkcie. Jeżeli ulokalnianie polega tylko na zmianach w zawartości grafiki i tekstów – to testowanie można ograniczyć do powierzchownej walidacji. Jeśli jednak – z powodu złej architektury systemu albo innych problemów – kod musiał także ulec zmianie, testowanie musi to wziąć pod uwage i skontrolować zarówno treść jak i działanie funkcji.
1 To samo pytanie pojawia się przy każdym testowaniu konfiguracji, a jeszcze ogólniej – przy każdym testowaniu regresywnym, niezależnie od jego przyczyn (przyp. tłumacza).
Decyzja, jaka jest wymagana ilość testowania ulokalnienia, jest decyzją ryzykowną – jak zresztą całe testowanie. Nabierając doświadczenia w testowaniu, uczymy się, co brać pod uwagę w procesie podejmowania decyzji.
Meteodą niekiedy stosowaną przez zespoły testujące, jest testowanie na ile produkt – mający w przyszłości podegać ulokalnieniu – nadaje się do ulokalnienia. Testuje się już pierwszą wersję produktu, zakładając że ulokalnienia zostanie wykonane poźniej. Testerzy stosujący metody szklanej skrzynki badają kod w poszukiwaniu ciągów znaków, właściwego przetwarzania jednostek miar, rozszerzonych znaków i innych zagadnień widocznych na poziomie kodu źródłowego. Czasem nawet robi się własną, „lipną” ulokalnioną wersję. Testerzy stosujący metody czarnej skrzynki starannie badają specyfikacje i sam produkt pod kątem takich problemów jak teksty w grafice albo kwestie konfiguracji. Można treż użyć „lipnej” wersji w celu przetestowania kompatybilności.
W ten sposób, zanim prawdziwe ulokalnienie zostanie dokonane, kłopoty które pojawiłyby się później zostały już wcześniej usunięte, dzięki czemu uloklanienie przebiega później łatwiej i taniej. Podsumowanie
Ha Ön egy rátermett és képzett softver ismerő, és folyékonyan egy nyelvet aż Angolon kívul, Ön egy nagyon piacképes szakképzett személy.
To jest znane już zdanie cytowane na początku tego rozdziału, tym razem napisane po węgiersku. Jeśli nie umie się go przeczytać, nie ma zmartwienia. Dowiedzieliśmy się przecież, że znajomość języka to tylko jedna z wielu umięjętności potrzebnych, by testować produkt poddany ulokalnieniu. Znaczną część pracy wykonuje się kontrolując, na ile produkt nadaje się do ulokalnienia oraz testując sprawy niezależne od języka.
Znając inne języki oprócz angielskiego, i czytając tę książkę aż do końca, żeby nauczyć się jak najwięcej na temat testowania oprogramowania, będzie się miało – jak to przeczytaliśmy przed chwilą po węgiersku – „zespół bardzo dobrze się sprzedających umiejętności”.
Więcej wiadoamości na teamt programowania ulokalnienia i testowania dla Windowsów można znaleźć w www.microsoft.com/globaldev. Dla Macintosha, wiadomości można znaleźć w książce Guide to Macintosh Software Localization, opublikowanej przez Addison-Wesley. Pytania
Pytania mają na celu ułatwienie zrozumienia. W aneksie A „Odpowiedzi na pytania” znajdują się prawidłowe rozwiązania – ale nie należy ściągać! 1.Jaka jest różnica między tłumaczeniem a ulokalnieniem?
2.Czy musi się znać język, aby móc testować produkt poddany ulokalnieniu? 3.Co to jest rozszerzanie tekstu i jakie błedy powoduje? 4.Podaj kilka dziedzin, w których rozszerzony zbór znaków może spowodować kłopoty. 5.Dlaczego tekstowe ciągi znaków należy trzymać poza kodem? 6.Wymień kilka rodzajów formatów danych, które mogą się różnić w różnych ulokalnionych wersjach programu.
 Rysunek 9.1 Kopmatybilność wiążąca razem kilka różnych typów aplikacji szybko staje się bardzo skomplikowana.
Rysunek 9.1 Kopmatybilność wiążąca razem kilka różnych typów aplikacji szybko staje się bardzo skomplikowana.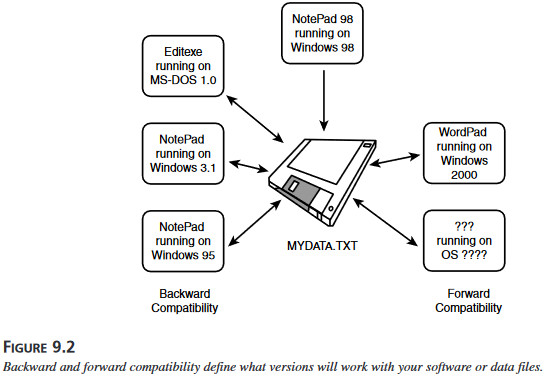 Rysunek 9.2 pokazuje, jak plik tekstowy zrobiony przy pomocy Notpad 98 w systemie Windows 98 jest kompatybilny wstecz aż do MS-DOS 1.0. Jest również kopmatybilny wprzód do Windows 2000 i prawdopodobnie pozostaniem takim również w kolejnych wersjach.
Rysunek 9.2 pokazuje, jak plik tekstowy zrobiony przy pomocy Notpad 98 w systemie Windows 98 jest kompatybilny wstecz aż do MS-DOS 1.0. Jest również kopmatybilny wprzód do Windows 2000 i prawdopodobnie pozostaniem takim również w kolejnych wersjach.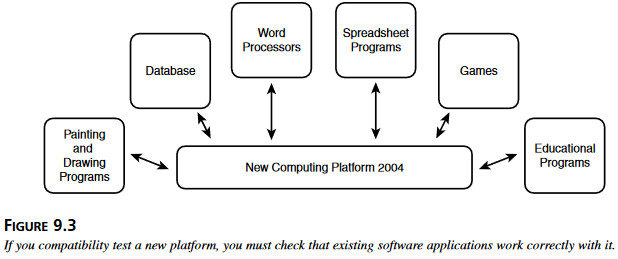 Rysunek 9.3 Testując kompatybilność nowej platformy, musi się skontrolować, że wszystkie istniejące aplikacje dziłają na niej prawidłowo.
Rysunek 9.3 Testując kompatybilność nowej platformy, musi się skontrolować, że wszystkie istniejące aplikacje dziłają na niej prawidłowo.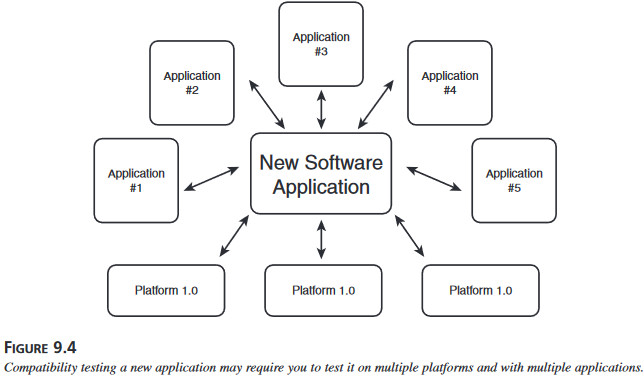 (rysunek 9.4). Trzeba podjąć decyzje, na jakich wersjach platformy i z jakimi innymi programami trzeba przetestwować aplikację.
(rysunek 9.4). Trzeba podjąć decyzje, na jakich wersjach platformy i z jakimi innymi programami trzeba przetestwować aplikację. Rysunek 9.5 Znak „Cerytfikowany dla Microsoft Windows” oznacza, że oprogramowanie spełnia wszystkie kryteria zdefiniowane przez zbiór norm.
Rysunek 9.5 Znak „Cerytfikowany dla Microsoft Windows” oznacza, że oprogramowanie spełnia wszystkie kryteria zdefiniowane przez zbiór norm.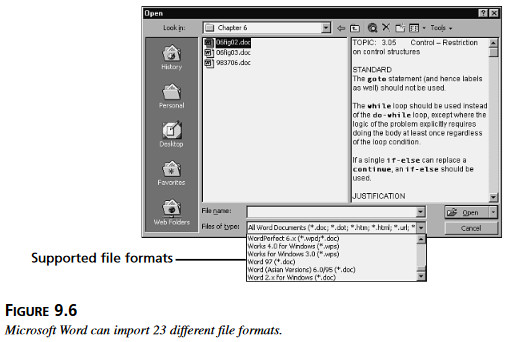 Rysunek 9.6 pokazuje okno dialogowe Otworzyć Plik w programie Word Microsoftu – i kilka spośród 23 różnych formatów plików, które można importować do tego programu.
Rysunek 9.6 pokazuje okno dialogowe Otworzyć Plik w programie Word Microsoftu – i kilka spośród 23 różnych formatów plików, które można importować do tego programu.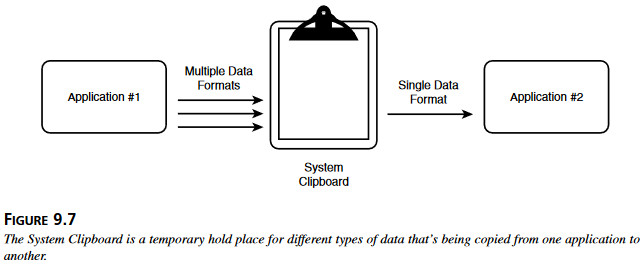 Rysunek 9.7 Schowek Systemowy służy do tymczasowego przechowywania różnych typów danych, które kopiuje się z jednego programu do drugiego.
Rysunek 9.7 Schowek Systemowy służy do tymczasowego przechowywania różnych typów danych, które kopiuje się z jednego programu do drugiego.