rozdział 8
08 września 2019, 21:50
Część III Zastosowanie umiejętności w praktyce
Na urodziny dostałem nawilżasz i osuszacz… Wstawiłem je do jednego pokoju i zostawiłem, żeby się ze sobą rozprawiły.
Steven Wright, komik
Odkrycie polega na tym, że patrzy się na to samo co inni i myśli coś innego.
Albert Szent-Gyorgyi, laureat nagrody Nobla w medycynie i fizjologii w 1937 roku
W TEJ CZĘŚCI Testowanie konfiguracji Testowanie kompatybilności Testowanie różnych wersji językowych Testowanie łatwości korzystania Testowanie dokumentacji Testowanie witryn WWW
Rozdział 8 Testowanie konfiguracji
W TYM ROZDZIALE Przegląd testowania konfiguracji Jak podejść do zadania Jak zdobyć potrzebny sprzęt Jak zidentyfikować standardy sprzętu Testowanie konfiguracji innych typów sprzętu
Życie mogłoby być takie proste. Sprzęt komputerowy mógłby być tylko jednego rodzaju. Wszelkie oprogramowanie mogłoby być wytwarzane przez tylko jedną firmę. Nie byłoby wtedy tych wszystkich mylących przycisków do wyboru opcji do klikania i pól wyboru do wybierania. Wszystkie interfejsy pasowałyby od początku doskonale – dla każdego. Jakie nudne1.
W rzeczywistym świecie, w mających po kilka tysięcy metrów kwadratowych powierzchni supermarketach komputerowych, stoją do wyboru komputery, drukarki, monitory, karty komunikacyjne, modemy, skanery, kamery cyfrowe, urządzenia peryferyjne i setki innych komputerowcyh gadżetów – wszystkie dające się podłączyć do komuotera domowego!
Dla początkującego testera, jednym z pierwszych zadań może być testowanie konfiguracji: sprawdzenie, że oprogramowanie działa z jak największą ilością różnych kombinacji sprzętu. Również testując inne rodzaje systemów niż najpopularniejsze „pecety” i Macintosh‘e, zagadnienie konfiguracji trzeba wziąć pod uwagę. Umiejętności opisane w tym rozdziale z łatwością można dostosować do takiej sytuacji.
Pierwsza część rozdziału opisuje ogólne zasady testowania konfiguracji komputerów osobistych, a potem przechodzi się do szczegółów na temat testowania drukarek, kart wideo i kart dźwiękowych. Chociaż przykłady dotyczą komputerów osobistych, opisane metody można łatwo przenieść na prawie każde rodzaje testowania konfiguracji. Każdego dnia powstają nowe typy urządzeń i zadaniem testerów jest wymyślić sposoby ich testowania.
Najważniejsze punkty tego rozdziału: 1. Czemu testowanie konfiguracji jest konieczne 2. Czemu testowanie konfiguracji bywa ogromnie pracochłonne 3. Podstawowe sposoby testowania konfiguracji
1 Czytelnikom polskim należącym do troszeczkę starszego niż najmłodsze pokolenia przypominają się może czasy bardzo zbliżone do tego “ideału”. Wcale jednak nie było tak nudno…
4. Jak wejść w posiadanie potrzebnego sprzętu 5. Jak postępować testując inne rodzaje oprogramowania niż dla komputerów osobistych Przegląd testowania konfiguracji
Będąc z następną wizytą w sklepie komputerowym, warto przyjrzeć się pudełkom i poczytać opisy wymagań systemowych. Znajdzie się wśród nich takie jak PC z procesorem 486/66 MHz, Super VGA, 256-kolorowy ekran, 16-bitowa karta dźwiękowa, port MIDI dla gier itd. Testowanie konfiguracji to proces kontrolowania, czy testowane oprogramowanie działa z tymi wszystkimi rozmaitymi rodzajami sprzętu. Warto rozważyć różne możliwe konfiguracje standardowego komputera osobistego, jaki stoi w wielu domach i w prawie każdym biurze: 6. Komputer. Są dziesiątki znanych producentów: Compaq, Dell, Gateway, Hewlett-Packard, IBM i wielu innych. Każdy producent konstruuje i produkuje komputery osobiste albo z komponentów własnej konstrukcji, albo z części kupionych od innych producentów. Własne komputery osobiste produkuje też wielu mniej znanych, małych producentów; robią je nawet hobbyści-amatorzy. 7. Komponenty. Większość komputerów osobistych ma modułową budowę. Składają się z kart głównych, kart dodatkowych i rozmaitych urządzeń takich jak stacje dysków, stacje CDROM, wideo, dźwięk, modem, karty sięciowe (rysunek 8.1). Istnieją karty telewizyjne i wyspecjalizowane karty do nagrywania wideo, do automatyzacji urządzeń domowych itd. Istnieją nawet karty wejścia i wyjścia, które są w stanie zamienić komputer osobisty w jednostkę zdolną pokierować niewielką fabryką. Urządzenia wewnętrzne są wytwarzane przez setki różnych producentów.
stacja dyskietek stacja dysku twardego urządzenie dopasowujące I/O stacja CD-ROM adapter wyświetlacza zasilacz magistrala jednostka systemowa karta główna. Rysunek 8.1 Liczne wewnętrzne komponenty składają się na konfigurację PC.
Rysunek 8.1 Liczne wewnętrzne komponenty składają się na konfigurację PC.
8. Urządzenia peryferyjne. Rysunek 8.2 pokazuje drukarki, skanery, mysz, klawiaturę, monitory, aparaty fotograficzne, kamery, joysticki i inne urządzenia, które podłącza się do komputera i które działają poza nim.
skaner drukarka joystick (manipulator) jednostka główna kamera cyfrowa mysz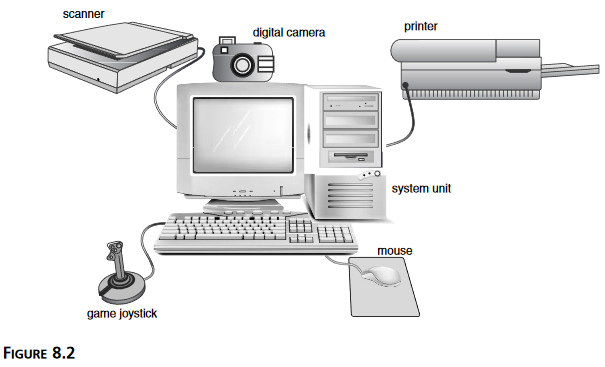 Rysunek 8.2 Komputer osobisty można podłączyć do rozmaitych urządzeń peryferyjnych. 9. Interfejsy. Komponenty i urządzenia peryferyjne podłącza się do do komputera przez różne rodzaje złączy (rysunek 8.3). Interfejsy mogą być wewnętrzne albo zewnętrzne. Ich nazwy: ISA, PCI, USB, PS/2, RS/232, Firewire. Istnieje tak wiele różnych możliwości, że producenci niekiedy produkują to samo urządzenie pod różnymi nazwami. Na przykład ten sam model myszy można często kupić w trzech różnych konfiguracjach! 10.Opcje i pamięć. Wiele komponentów i urządzeń peryferyjnych można kupić z różnymi opcjami sprzętu i wielkościami pamięci. Drukarkę można uaktualnić, żeby obsługiwała więcej wzorów liter albo używała więcej pamięci, żeby drukowanie szło szybciej. Karty graficzne mające więcej pamięci potrafią obsługiwać dodatkowe kolory i grafikę o większej rozdzielczości. 11. Programy obsługi. Wszystkie komponenty i urządzenia peryferyjne komunikują się z systemem operacyjnym i z aplikacjami za pomocą procedur na niskim poziomie, zwanych programami obsługi. Często dostarczone są one przez producenta sprzętu i instaluje się je w trakcie procesu ustawiania sprzętu. Chociaż w sensię technicznym programy obsługi są oczywiście oprogramowaniem, z punktu widzenia testu zalicza się je do konfiguracji sprzętu.
Rysunek 8.2 Komputer osobisty można podłączyć do rozmaitych urządzeń peryferyjnych. 9. Interfejsy. Komponenty i urządzenia peryferyjne podłącza się do do komputera przez różne rodzaje złączy (rysunek 8.3). Interfejsy mogą być wewnętrzne albo zewnętrzne. Ich nazwy: ISA, PCI, USB, PS/2, RS/232, Firewire. Istnieje tak wiele różnych możliwości, że producenci niekiedy produkują to samo urządzenie pod różnymi nazwami. Na przykład ten sam model myszy można często kupić w trzech różnych konfiguracjach! 10.Opcje i pamięć. Wiele komponentów i urządzeń peryferyjnych można kupić z różnymi opcjami sprzętu i wielkościami pamięci. Drukarkę można uaktualnić, żeby obsługiwała więcej wzorów liter albo używała więcej pamięci, żeby drukowanie szło szybciej. Karty graficzne mające więcej pamięci potrafią obsługiwać dodatkowe kolory i grafikę o większej rozdzielczości. 11. Programy obsługi. Wszystkie komponenty i urządzenia peryferyjne komunikują się z systemem operacyjnym i z aplikacjami za pomocą procedur na niskim poziomie, zwanych programami obsługi. Często dostarczone są one przez producenta sprzętu i instaluje się je w trakcie procesu ustawiania sprzętu. Chociaż w sensię technicznym programy obsługi są oczywiście oprogramowaniem, z punktu widzenia testu zalicza się je do konfiguracji sprzętu.
 Rysunek 8.3 Tył komputera osobistego zawiera liczne złącza do przyłączania urządzeń peryferyjnych.
Rysunek 8.3 Tył komputera osobistego zawiera liczne złącza do przyłączania urządzeń peryferyjnych.
Tester przygotowujący się do rozpoczęcia testowania konfiguracyjnego jakiegoś programu, powinien rozważyć jaka konfiguracja będzie najbardziej typowa dla tego programu. Gra komputerowa z mnóstwem efektów graficznych będzie wymagała zwrócenia uwagi na wideo i dźwięki. program do robienia kolorowych widokówek będzie szczególnie uzależniony od drukarek. program faksowy lub telekomunikacyjny należy przetestować z różnymi typami modemów i konfiguracji sięci.
Czemu właściwie miałoby to wszystko być konieczne? Istnieją przecież standardy, które dotyczą w jednakowym stopniu komputera osobistego kupowanego w supermerkecie i specjalnego komputera w szpitalu. Można chyba oczekiwac, że jeśli sprzęt został skonstruowany zgodnie ze standardami, to oprogramowanie powinno po prostu na nim działać bez żadnych kłopotów. W świecie idealnym pewnie by tak było, ale niestety - w rzeczywistości standardy nie zawsze są przestrzegane. Niektóre standardy są dość luźne – nazwijmy je zbiorami dobrowolnych reguł. Producenci kart i urządzeń peryferyjnych działają w sytuacji ostrej konkurencji i często naginają zasady, aby wcisnąc w swój produkt jeszcze jedną nową funkcję albo jeszcze odrobinę wyższą wydajność. Często programy obsługi do nowych urządzeń wrzuca się do pudełka niemal w momencie, gdy dostawy sprzętu zaczynają opuszczać bramy fabryki. W wyniku tego nie raż się zdarza, że oprogramowanie nie działa z niektórymi konfiguracjami sprzętu.
Lokalizacja błędów konfiguracji
Błędy konfiguracji mogą być naprawdę bolesne. Pamiętamy przecież jeszcze błąd „Króla Lwa” opisany w rozdziale 1-ym? To był typowy problem konfiguracji. Dźwięk programu nie działał na kilku zaledwie, ale bardzo popularnych konfiguracjach sprzętu. Ktokolwiek grał w grę komputerową albo posługiwał się aplikacja graficzną, kiedy kolory nagle oszalały, albo kawałki okna „odłupywały się” kiedy się je ciągnęlo, przypuszczalnie zetknął się z błędem programu obsługi karty graficznej. Ktokolwiek poświęcił długie godziny (albo dni!) usiłując zmusić stary program do działania z nową drukarką, też miał zapewne do czynienia z błędem konfiguracji.
Pewnym sposobem stwierdzenia, czy ma się do czynienia z błędem konfiguracji czy po prostu ze zwykłym błędem, jest powtórzenie dokładnie tego samego działania, krok po kroku, na innym komputerze z zupełnie odmienną konfiguracją. Jeśli awaria nie następuje, prawie na pewno mamy do czynienia z błędem konfiguracji. Jeśli awaria występuje na więcej niż jednej konfiguracji, to zapewne jest to „zwyczajny” błąd.
Przypuśćmy że testując program na jakiejś szczególnej konfiguracji natrafiamy na problem. Kto teraż powinien naprawić błąd – zespół wytwarzający oprogramowanie czy też producent sprzętu? Może tu chodzić o miliony dolarów.
Przede wszystkim trzeba zlokalizować problem. Zwykle wiąże się to z dynamicznym testowaniem metodami szklanej skrzynki i wysiłkiem znajdowania i naprawiania błędu. Problem konfiguracyjny może wystąpić z wielu różnych powodów, z których każdy wymaga starannego przebadania kodu działającego w różnych konfiguracjach: 12.Oprogramowanie może mieć błąd występujący w wielu różnych konfiguracjach. Na przykład, program do produkcji kartek z życzeniami może działać z drukarkami laserowymi, ale nie z atramentowymi. 13.Oprogramowanie może mieć błąd pojawiający się tylko w jednej, szczególnej konfiguracji – na przykład nie działa na modelu „OkeeDoKee BR549 super drukarki atramentowej”. 14.Urządzenie albo jego program obsługi zawiera ukryty błąd, który powoduje awarię tylko jednego programu. Może ten program jest jedynym, który używa jakichś ustawień karty wideo? Taki program w połączeniu z wadliwym modelem karty powoduje awarię. 15.Urządzenie albo jego program obsługi zawiera błąd, który wprawdzie widoczny jest z wieloma programami, ale szczególnie rzuca się w oczy z jednym z nich. Przykładem może być program obsługi drukarki, który jako wartość domyślną zawsze wybiera jakość roboczą wydruku, więc aplikacja musi go do każdego wydruku przestawiać na tryb druku wysokiej jakości.
W dwóch pierwszych przykładach zespół projektu wytwarzającego oprogramowanie jest oczywiście odpowiedzialny za naprawienie błędu.
W obu następnych przykładach sytuacja nie jest już oczywista. Powiedzmy że błąd jest błędem drukarki i że ten model jest najpopularniejszy na świecie – ma dziesięć milionów użytkowników. Niewątpliwie, program musi działać z tą właśnie drukarką. Chociaż program nie zawiera żadnego błędu, ale przypuszczalnie naprawę – w postaci jakiegoś obejścia tego błędu – i tak wykona zespół wytwarzający aplikację.
Niezależnie od źródła problemu, odpowiedzialność i tak spada na producenta aplikacji. Klienci nie będą chcieli słuchać tłumaczeń, że to wadliwy sprzęt jest przyczyną błędu, będą po prostu chcieli, żeby aplikacja działała na ich konfiguracji.
O kartach dźwiękowych
W 1997 roku Microsoft wypuścił na rynek lalkę AntiMates Barney wraż z oprogramowaniem na CD, mające uczyć dzieci programowania. Oprogramowanie kontaktowało się z lalką za pomocą dwukierunkowego łącza radiowego, umieszczonego w lalce i w komputerze osobistym.
Radio w komputerze było podłączone do rzadko używanego interfejsu kart dźwiękowych, zwanego złączem MIDI. Tego interfejsu używa się do podłączania sprzętu muzycznego. Microsoft wyszedł z założenia, że to łącze jest dobrym wyborem, gdyż większość posiadaczy komputerów osobistych nia ma tego rodzaju sprzętu muzycznego. Karta miałaby więc to złącze wolne, dostępne do podłączenia radia do komunikacji z lalką.
Podczas testowania konfiguracyjnego odkryto typową ilość błędów. Jedne były problemami karty dźwiękowej, inne błędami w oprogramowaniu ActiMates. Jednak jednego błędu nie udało się nigdy zlokalizować. Wyglądało na to, że od czasu do czasu, losowo, komputer osobisty nagle się zawieszał i wymagał ponownego wystartowania. Problem występował tylko z jednym typem karty dźwiękowej – najpopularniejszej na rynku (oczywioście).
Kiedy w harmonogramie pozostało jeszcze tylko kilka tygodni, podjęto wzmożone wysiłki żeby rozwiązać problem. Po intensywnym testowaniu konfiguracyjnyem i poszukiwaniu błędu, udało się znaleźć jego przyczynę – winna była karta. Wyglądało na to, że zlącze MIDI tej karty zawsze miało ten błąd, tylko że używano je na tyle rzadko, że błąd nigdy nie został odkryty. Oprogramowanie ActiMates ujawniło go po raż pierwszy.
Zrobił się wielki bałagan, pełno zaprzeczania i wzajemnego wytykania się palcami, i wiele pracy późno w nocy. W końcu producent kart dźwiękowych przyznał, że problem istniał i obiecał znaleźć obejście błędu w nowych wersjach programu obsługi. Microsoft zainstalował poprawiony program obsługi na CD-ROM sprzedawanym z lalką ActiMate i dokonał pewnych zmian w programie tak, żeby błąd rzadziej powodował awarie. Mimo tych wszystkich wysiłków, te właśnie problemy z kompatybilnością karty dźwiękowej były najczęstszym powodem późniejszych telefonów do serwisu.
Dobór wielkości zadania
Testowanie konfiguracyjne może być wielkim przedsięwzięciem. Wyobraźmy sobie testowanie nowej gry, która ma być wykonywana na Microsoft Windows. Gra ma mnóstwo grafiki, dużo efektów dźwiękowych, pozwala wielu graczom zmierzyć się ze sobą przy pomocy połączeń telefonicznych oraz wykonywać wydruk szczegółów gry dla celów planowania strategii.
Testowanie konfiguracji należy zaplanować co najmniej z różnymi kartami graficznymi, dźwiękowymi, modemami i drukarkami. Asystent funkcji Windows Dodaj nowy sprzęt (rysunek 8.4) umożliwia wybranie sprzętu w każdej z tych kategorii – i jeszcz 25-ciu innych.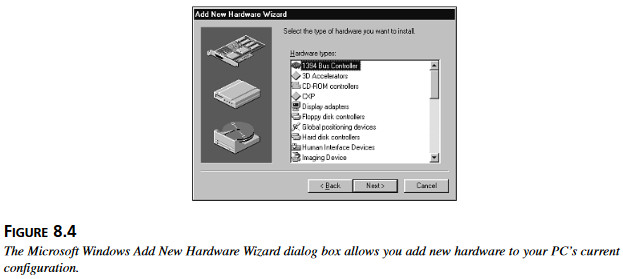 Rysunek 8.4 Okno dialogowe asystenta Dodaj Nowy Sprzęt umożliwia dodawanie nowych urządzeń do aktualnej konfiguracji PC.
Rysunek 8.4 Okno dialogowe asystenta Dodaj Nowy Sprzęt umożliwia dodawanie nowych urządzeń do aktualnej konfiguracji PC.
W każdej kategorii sprzętu znajduje się lista różnych producentów i modeli (rysunek 8.5). Pamiętajmy, że to są tylko rodzaje sprzętu, dla którch programy obsługi są wbudowane bezpośrednio w system Windows. Wielu innych producentów sprzętu dostarcza wraż ze sprzętem własne dyski z potrzebnym oprogramowaniem.
 Rysunek 8.5 Każdy rodzaj sprzętu ma wielu różnych producentów i wiele modeli.
Rysunek 8.5 Każdy rodzaj sprzętu ma wielu różnych producentów i wiele modeli.
Chcąc przeprowadzić pełny, obejmujący wszelkie możliwości test konfiguracji, kontrolujący wszelkie rodzaje i modele sprzętu, ma się olbrzymią robotę.
Istnieje w przybliżeniu 336 różnych kart graficznych, 210 kart dźwiękowych, 1500 modemów i 1200 drukarek. Ilość kombinacji testowych wynosi więc 336 x 210 x 1500 x 1200, co daje iloczyn rzędu miliardów – zbyt wiele by móc poważnie o tym myśleć !
Jeśli ograniczyć testowanie tak, by wykluczyć wszelkie kombinacje, tylko testować każdy rodzaj karty osobno, poświęcając około 30 minut na każdą konfigurację, byłoby się gotowym po upływie około roku. Pamiętajmy, wyliczenie dotyczny tylko jednego wykonania testów przez wszelkie kombinacje, a przecież często – uwzględniwszy dostawy z naprawami błędów – trzeba wykonać dwa lub trzy wykonania testów, dopóki produkt nie będzie ostatecznie wypuszczony na rynek.
Rozwiązaniem tego bałaganu jest – czego (należy mieć nadzieję) czytelnik już się domyśla – podział na klasy równoważności. Trzeba znaleźć sposób, jak ograniczyć olbrzymi zbiór wszelkich możliwych konfiguracji tak, aby pozostały tylko najważniejsze. Oczywiście nie testując wszystkiego trzeba będzie podjąć pewne ryzyko, ale przecież właśnie na tym polega test oprogramowania. Jak podejść do zadania
Proces podejmowania decyzji, które urządzenia należy przetestować i w jaki sposób jest w zasadzie nieskomplikowanym zastosowaniem podziału na klasy równoważności. Najważniejsze – kluczowe dla powodzenia projektu – jest znalezienie właściwej informacji przed podjęciem decyzji. Jeśli brak nam doświadczenia z rodzajem sprzętu, jaki testowany program wykorzystuje, trzeba się nauczyć samemu ile się da oraz poprosić innych, doświadczonych testerów i programistów o pomoc. Trzeba zadawać wiele pytań i upewnić się, czy propozycje zostały zaakceptowane.
Następne podrozdziały opisują ogólny proces planowania testowania konfiguracji.
Zdefiniowanie potrzebnych rodzajów sprzętu
Czy aplikacja robi wydruki? Jeśli tak, trzeba będzie przetestować drukarki. Jeśli ma efekty dźwiękowe, trzeba będzie testować karty dźwiękowe. Jeśli jest to program graficzny albo fotograficzny, pewnie przydadzą się skanery i cyfrowe aparaty fotograficzne. Warto uważnie poznać funkcje programu, aby upewnić się, czy niczego ważnego się nie pominąęło w trakcie planowania. Trzeba przez chwilę zastanowić się, czego ten program będzie potrzebował do działania.
Interakcyjna rejestracja
Przykładem funkcji, którą łatwo przeoczyć przy planowaniu, jaki sprzęt należy przetestować, jest rejestracja interakcyjna. Wiele programów umożliwia dzisiaj użytkownikom dokonanie rejestracji podczas instalacji przez modem. Użytkownik wpisuje swoje nazwisko, adres i inne dane, klika na przycisk, a modem dzwoni do komputera i producenta, który przesyła potrzebną informację i dokonuje rejestracji. Nawet jeśli program nie używa takiego połączenia do żadnej innej pracy oprócz interakcyjnej rejestracji, trzeba zastanowić się, czy modemy mają być częścią testowania konfiguracyjnego.
Zadecydować jakie są dostępne marki, modele i programy obsługi urządzeń
Ten kto wytwarza ostry program graficzny, nie będzie chyba chciał testować jego wydruków na czarno-białej drukarce mozaikowej z roku 1987-ego (pamiętacie je jeszcze?). Listę sprzętu do testowania konfiguracji warto skompilować wspólnie ze sprzedawcami i z osobami zajmującymi się marketingiem. Jeśli nie mogą lub nie chcą pomóc, warto złapać kilka aktualnych i starszych numerów tydnika „PC” i zorientować się, jakie rodzaje sprzętu są dostępne i co było – i jest – popularne. Tego typu czasopisma często publikują różnego rodzaju listy i porównania drukarek, kart dźwiękowych i graficznych.
Warto się zorientować, które z tych urządzeń są klonami i dlatego naeżącymi do tej samej klasy równoważności co oryginał. Zdarza się, że producent drukarek sprzedaje swoje drukarki innej firmie, która następnie umieszcza na nich swoją etykietkę. Z punktu widzenia testowania konfiguracji, mamy do czynienia z tą samą drukarką.
Trzeba też wziąć pod uwagę, które programy obsługi wykorzystać podczas testowania. Do wyboru ma się zwykle program obsługi będący częścią systemu operacyjnego, program dostarczany razem z urządzeniem oraz najnowszą wersję programu obsługi dostępną na Internecie, na stronie producenta urządzenia lub systemu operacyjnego. Zwykle są to trzy różne programy. Trzeba sobie samemu zadać pytanie, co klienci mają lub będą mieć.
Zdefiniowanie możliwych cech, trybów pracy i opcji
Kolorowe drukarki potrafią drukować czarno-biało albo w kolorze, w różnych trybach jakości, mogą też mieć ustawienia dla drukowania fotografii albo tekstu. Karty graficzne, jak pokazano na rysunku 8.6, mogą użuwać różnych ustawień kolorów i różnej rozdzielczości.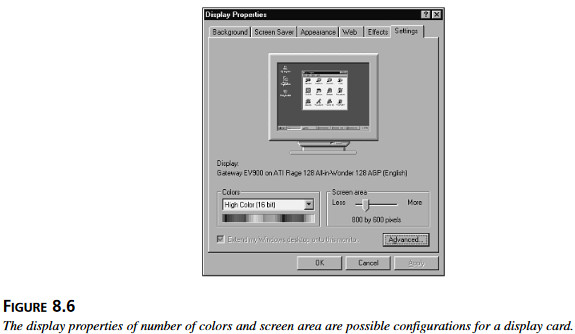 Rysunek 8.6 Różne odmiany kolorów i inne właściwości ekranu to przykłady możliwych konfiguracji karty graficznej.
Rysunek 8.6 Różne odmiany kolorów i inne właściwości ekranu to przykłady możliwych konfiguracji karty graficznej.
Każde urządzenie ma rozmaite opcje. Testowany program nie musi wykorzystywać wszystkich opcji urządzenia. Dobrym przykładem są gry komputerowe. Wiele z nich wymaga pewnej minimalnej ilości kolorów i pewnej minimalnej rozdzielczości, bez których nie będą działać.
Zmniejszenie liczby konfiguracji do dającej się opanować ilości
Przy założeniu, że nie ma się do dyspozycji czasu ani budżetu by przetestować wszystko, musi się zredukować tysiące możliwych konfiguracji do najważniejszych – tych które się rzeczywiście przetestuje.
Sposobem może być wprowadzenie wszelkich informacje na temat konfiguracji do arkusza kalkulacyjnego, gdzie kolumy oznaczają producenta, model, wersję programu obsługi i wartość opcji. Rysunek 8.7 pokazuje przykład tabeli, która opisuje różne konfiguracje drukarek. Zespól testowy lub jego szef może zapoznać się arkuszem i zdecydowac, jakie konfiuguracje chce się testować.
Popularność (1=największa, 10=najmniejsza)
Typ (laser/atramentowa)
Wiek (w latach)
Producent
Model
Wersja programu obsługi
Opcje
Opcje
1 Laser 3 XXX LDYI2000 1.0 Czarnobiały
Roboczy
Wysokiej jakości
5 Atramento wy
1 XXX IJDIY2000 1.0a Kolor Roboczy
Czarnobiały
Wysokiej jakości Roboczy Wysokiej jakości
5 Atramento wy
1 XXX IJDIY2000 2.0 Kolor Arytstyczny
Czarnobiały
Fotografia
Roboczy Wysokiej jakości
10 Laser 5 YYY LJ100 1.5 Czarnobiały
100 dpi
200 dpi 300 dpi
Atramento wy
2 YYY EasyPront 1.0 Auto 600 dpi
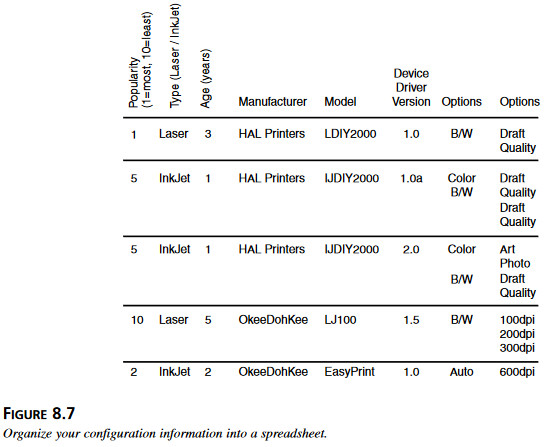 Rysunek 8.7 Warto wprowadzić dane na temat konfiguracji do arkusza kalkulacyjnego.
Rysunek 8.7 Warto wprowadzić dane na temat konfiguracji do arkusza kalkulacyjnego.
Warto zwrócić uwagę, że tabela na rysunku 8.7 ma także kolumny na informacje o popularności urządzenia, jego typie i wieku. Konstruując klasy równoważności, można np. podjąć decyzję, że będzie się testowało tyko najpopularniejsze rodzaje drukarek, albo tyko te modele, które mają mniej niż pięć lat. Na podstawie informacji o typie – w tym przykładzie, laserowa albo atramentowA – można zadecydować, że przetestuje się 75% drukarek laserowych i 25% - atramentowych.
Niestety, proces decyzyjny, gdzie dzieli się możliwe konfuguracje na mniejsze klasy równoważności, zależy od wyboru dokonanego przez zespół projektowy. Nie istnieje jedna, wyłącznie poprawna reguła. Każdy projekt wytwarzania oprogramowania jest inny i niełatwo będzie dobrać kryteria klasyfikacji. Wystarczy upewnić się, że każdy w zespole, a zwłaszcza kierownik projektu, zawiadomieni są o tym, co się testuje i w jaki sposób wybrane zostały testowe zmienne, których wartość zadecydowała o podziale.
Zidentyfikowanie tych szczególnych cech oprogramowania, których działanie zależy od konfiguracji sprzętu
Najważniejsze słowo w tytule to szczególne. Nie chodzi o to, by kompletnie przetestować całą aplikację na każdej możliwej konfiguracji. Wystarczy przetestować tylko te cechy, których działanie zależy od sprzętu.
Na przykład, testując program do przetwarzania tekstu taki jak WordPad (zob. rysunek 8.8), nie trzeba będzie np. testować zapisywania i ładowania plików w każdej z konfiguracji. Zapisywanie i ładowanie plików nie ma nic wspólnego z drukowaniem. Dobre dane testowe składałyby się z dokumentu, zawierającego rozmaite (wybrane – oczywiście – przy pomocy podziału na klasy równoważności) czcionki, wielkości, kolory, ilustracje w tekście i tak dalej. Ten dokument drukowałoby się na wszystkich konfiguracjach drukarek.  Rysunek 8.8 Do przetestowania konfiguracji drukarek można używać dokumentu zawierającego różne czcionki i style.
Rysunek 8.8 Do przetestowania konfiguracji drukarek można używać dokumentu zawierającego różne czcionki i style.
Wybranie funkcji zależnych od konfiguracji i sprzętu może być trudniejsze niż się wydaje na pierwszy rzut oka. Należy zacząc od techniki czarnej skrzynki i przetestować oczywiste pod tym względem funkcje. Potem warto porozmawiać z innymi osobami z zespołu, zwłaszcza z programistami, aby uzyskać obraż „szklanoskrzynkowy”. Nie raż zdziwimy się, odkrywając jak na pozór odległe funkcje w jakimś stopniu mogą zależeć od konfiguracji sprzętu.
Skonstruowanie zadań testowych do użycia na każdej konfiguracji
Jak pisać zadania testowe będzie tematem rozdziału 17-ego, „Pisanie i śledzenie zadań testowych”. Już teraż jednak warto zdać sobie sprawę, że trzeba będzie zanotować wszystkie kroki potrzebne do przetestowania każdej z konfiguracji. Może to być tak proste jak poniższa lista: 1. Wybrać i ustawić kolejną konfigurację z listy 2. Wystartować oprogramowanie 3. Załadować plik configtest.doc. 4. Potwierdzić, że wyślwietlony plik jest prawidłowy 5. Wydrukować dokument 6. Potwierdzic, że nie ma żadnych komunikatów o błędach i że wydrukowany dokument zgodny jest ze standardem 7. Wszelkie rozbieżności notować jako błędy
W rzeczywistości, te instrukcje byłyby znacznie bardziej skomplikowane, zawierające więcej szczgółów na temat tego, co dokładnie należy zrobić. W końcu przecież autor tej specyfikacji nie chciałby osobiście wykonywać tych testów w przyszłości.
Wykonanie testów na każdej konfiguracji
Trzeba wykonać zadania testowe i starannie zarejestrować wyniki i napisać na ich podstawie raport (zob. rozdział 18-y, „Raportowanie tego, co się znalazło”) dla zespołu, a w razie konieczności – także dla producenta. Jak już napisano wcześniej, często zidentyfikowanie źródła problemu z konfiguracją jest trudne i czasochłonne. Trzeba współpracować z programistami i testerami stosującymi metody szklanej skrzynki aby znalęźć przyczyny awarii i zdecydować, czy spowodował ją błąd oprogramowania, czy błąd sprzętu.
Jeśli przyczyną awarii jest błąd sprzętu, należy poszukać w portalu internetowym producenta sposobu raportowania błędów sprzętu. Pisząc raport, warto przedstawić się jako tester oprogramowania i podać nazwę swego pracodawcy. Wiele firm ma osobny personel, który udziela pomocy firmom piszącym oprogramowanie używające ich sprzętu. Dla ułatwienia lokalizacji przyczyny błędu, producent sprzętu może prosić o przesłanie kopii oprogramowania, zadań testowych i szczegółów na temat okoliczności zaistnienia awarii.
Ponowne wykonywanie zadań testowych aż do skutku
Często test konfiguracji ciągnie się przez cały czas trwania projektu. Początkowo próbuje się kilka konfiguracji, potem pełny zestaw, potem znów tylko wybrane konfiguracje dla zweryfikowania zrobionych poprawek. W końcu nadchodzi moment, kiedy nie ma już więcej znanych błędów, a pozostałe błędy występują w rzadkich i mało prawdopodobnych konfiguracjach. W tym momencie są podstawy, aby uznać testowanie konfiguracji za zakończone. Jak zdobyć potrzebny sprzęt
Nie mówiliśmy jeszcze dotąd jak wejść w posiadanie całego tego sprzętu. Nawet dokonując pracochłonnej – i ryzykownej – redukcji zestawu klas równoważności do niezbędnego minimum, nadal potrzebuje się dziesiątek różnych zestawów sprzętu. Kupić wszystko w sklepie jest kosztownym rozwiązaniem, zwłaszcza jeśli niektóre elementy sprzętu użyje się tylko raz. Oto kilka sposobów, aby rozwiązać ten kłopot: 16.Kupuje się tylko tę konfigurację, której się będzie używało najczęściej. Doskonałą metodą jest, aby każdy tester w zespole posługiwał się innym sprzętem. To może doprowadzić działy zaopetrzeniowy i administratorów systemu do szału (dla nich jest najlepiej, aby każdy przcownik posługiwał się identyczną konfiguracją), ale to bardzo skuteczny sposób, aby zawsze móc testować na różnych konfiguracjach. Nawet w małym zespole, mieć do dyspozycji trzy – cztery różne konfiguracje jest bardzo cenne.
17.Warto skontaktować się z producentami i spróbować pożyczyć czy wręcz dostać sprzęt. Jeśli wytłumaczyć, że testuje się nowe oprogramowanie i chce się upewnic, czy działa na ich sprzęcie, wielu producentów może się zgodzić. Oni są również zainteresowani wynikami, więc można im obiecać przekazanie wyników testów, a jak się da – również kopię gotowego oprogramowania. Warto stworzyć dobre relacje, zwłaszcza jeśli znalazło się błąd i potrzenbujemy u producenta kogoś, komu można przekazać informację o błędzie. 18.Można wysłać pocztę komputerową do wszystkich w swojej firmie, z pytaniem jakiego sprzętu używają w pracy, a nawet w domu, i czy pozwoliliby wykonać na nim kilka testów. Wykonując w ten sposób testowanie konfiguracji, trzeba będzie się najeździć, ale ileż to taniej niż kupowanie wszystkiego samemu.
Testowanie konfiguracji magnetowidu
Animowane lalki Microsoftu „ActiMates” miały intefejs nie tylko do PC, ale również do magnetowidu. Specjalne „pudełko” dołączone do magnetowidu odczytywało komendy i wysysłało je do lalki drogą radiową. Zespół testujący miał do dyspozycji wiele konfiguracji PC, ale żadnego magnetowidu.
Znaleziono dwa sposoby rozwiązania problemu:
Poproszono ponad 300 pracowników, aby przynieśli do pracy swoje magnetowidy. Kierownik ogłosił drobne nagrody dla zachęcenia uczestników.
Zapłacono kierownikowi w lokalnym sklepie z elektroniką , aby pozostał w pracy po godzinach. W tym czasie testerzy wyciągali z półki każdy magnetowid, podłączali sprzęt i wykonywali test. Każdy pożyczony magnetowid zostł dodatkwo odkurzony i oczyszczony, a kierownikowi który się na to zgodził zafundowano dobry obiad.
Kiedy wszystko było już gotowe, przetestwoano ponad 150 magnetowidów, które stanowiły dobrą klasę równoważności dla magnetowidów posiadanych przez ludzi.
19.Kto dysponuje własnym budżetem, może spróbować wynająć do testowania zajmujące się zawodowo testowaniem kompatybilności i konfiguracjji laboratorium1. Te firmy zajmują się wyłącznie testowaniem konfiguracji i mają do dyspozycji wszelki znany ludzkości sprzęt PC. No, może nie aż tyle, ale prawie.
Taka firma często jest w stanie pomóc dokonać wyboru właściwego sprzętu, na którym przeprowadzi się testowanie. Następnie ma się do dyspozycji dwie opcje: albo samemu wykonuje się testowanie na sprzęcie firmy, albo można też zakupić pełną usługę. Klient dostarcza oprogramowanie, instrukcje testowanie oraz oczekiwane wyniki. Od tego miejsca pracę przejmuje firma, wykonuje testy i sporządza raporty, które zadania testowe przeszły, a które nie. Bywa to kosztowne, ale na pewno mniej kosztowne niż kupowanie całego sprzętu albo brak testowania i klienci znajdujący błędy. Jak zidentyfikować standardy sprzętu
Kto chciałby poświęcić nieco czasu analizie metodami czarnej skrzynki – to znaczy przejrzeć specyfikacje, używane przez firmy wytwarzające sprzęt komputerowy – może szukać w kilku miejscach. Znając nieco lepiej specyfikację sprzętu będziemy mogli dokonać bardziej świadomego wyboru najwłaściwszych klas równoważności.
Dla sprzętu Apple‘a trzeba zajrzeć na stronę http//:developer.apple.com/hardware. Znajdzie się tam dołączenia na temat wytwarzania i testowania sprzętu i programów obsługi dla komputerów Apple. Inne dołączenie Apple‘a, http://developer.apple.com/testing, zawiera wiadomości na temat testowania, a także dołączenia do laboratoriów zajmujących się testowaniem konfiguracji.
Dla komputerów osobistych, najlepsze dołączenie to http://www.pcdesignguide.org/. Tę witryne sponsorują wspólnie Intel i Microsoft. Znaleźć tam można wiadomości i dołączenia do standardów stosowanych do wytwarzania sprzętu i urządzeń peryferyjnych dla PC. Standardy podlegają corocznej rewizji i otrzymują nazwy PC99, PC2000 i tak dalej.
Micorsoft publikuje zestawienia standardów dla oprogramowania i sprzętu ubiegającego się o znak firmowy Windows. Ta informacja znajduje się na http://msdn.micorsoft.com/certification oraz na http://www.microsoft.com/hwtest. Testowanie konfiguracji innych typów sprzętu
1 Możliwość na razie niedostępna na rynku polskim (przyp. tłumacza).
Cóż więc począć, jeśli testuje się oprogramowanie na innych komputerach niż PC i Mac? Czy cały ten rozdział był marnowaniem czasu? W żadnym razie. Wszystko, czegośmy się tutaj nauczyli, daje się zastosować także do testowania własnych systemów firmowych. Nieważne, o jaki chodzi sprzęt i oprogramowanie, do czego podłączone. Jeśli coś podłączone jest do czegokolwiek innego, testowanie konfiguracji staje się potrzebne.
Testując oprogramowanie dla systemu wbudowanego, sieci, urządzenia medycznego czy systemu telefonicznego, należy sobie zadać te same pytania, co dla komputera osobistego: 20.Jaki zewnętrzny sprzęt będzie pracował z tym oprogramowaniem? 21.Jakie są dostępne modele i wersje tego sprzętu? 22.Jakie funkcje i opcje obsługuje dany sprzęt?
Należy najpierw stworzyć klasy równoważności przy pomocy wiadomości uzyskanych od osób pracujących na danym sprzęcie, kierowników projektów albo sprzedwaców. Następnie wytwarza się zadania testowe, gromadzi potrzebny sprzęt i wykonuje testy. Testopwanie konfiguracji stosuje się do tych samych zasad, których nauczyliśmy się już wcześniej. Podsumowanie
Ten rozdział nauczył nas myśleć na temat testowania konfiguracji. To zadanie często otrzymują do wykonania początkujący testerzy, ponieważ nietrudno je zdefiniować, jest dobrym wprowadzniem do podstawowych danych o firmie i do zastosowania podziału na klasy równoważności w praktyce. Ponadto to zadanie pozwoli na kontakt z wieloma innymi osobami z projektu, a kierownictwo bez trudu samo zweryfikuej jego wyniki. Ma też wadę – jest przygnebiająco rozległe.
Jeśli otrzymało się za zadanie test komnfiguracji w projekcie, należy wziąć głeboki oddech, ponownie przeczytać ten rozdział, uważnie zaplanować pracę i wykazać wiele cierpliwości. Kiedy wszystko będzie już gotowe, szef przyjdzie z kolejnym wyzwaniem: testowaniem kompatybilności, tematem kolejnego rozdziału. Pytania
Pytania mają na celu ułatwienie zrozumienia. W aneksie A „Odpowiedzi na pytania” znajdują się prawidłowe rozwiązania – ale nie należy ściągać! 1.Jaka jest różnica między komponentem a urządzeniem peryferyjnym? 2. Jak odróznić, czy błąd jest ogólnym problemem, czy też wyłącznie błędem konfiuracji? 3. Jak można zagwarentować, że program nigdy nie będzie miał błędów konfiguracji?
4. Prawda czy fałsz: klonowana karta dzwiękowa nie musi być poddana testowaniu konfiguracji. 5. Oprócz wieku oraz popularności, jakie inne kryteria można zastosować jako podstawę podziału na klasy równoważności? 6. Czy dopuszczalne jest wypuszczenie programu mającego błędy konfiguracji?
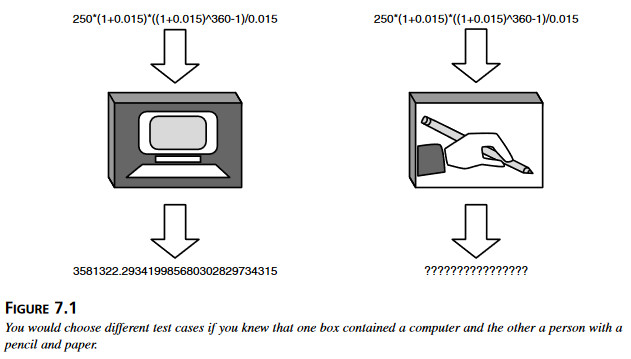 Jeśli nie wie się, jak działa pudełko, wybrałoby się dynamiczne techniki czarnej skrzynki, które zostały opisane w rozdziale 5-ym, „Testowanie z klapkami na oczach”. Gdyby jednak zajrzeć do pudełek i zobaczyć, że jedno z nich zawiera komputer, a w drugim ukrywa się człowiek z ołówkiem i papierem, wybrałoby się przypuszczalnie dla nich zupełnie odmienne zestawy testów. Oczywiście, to bardzo uproszczony przykład, ale dobrze ilustruje jak znajomość sposobu działania programu wpływa na sposób testowania.
Jeśli nie wie się, jak działa pudełko, wybrałoby się dynamiczne techniki czarnej skrzynki, które zostały opisane w rozdziale 5-ym, „Testowanie z klapkami na oczach”. Gdyby jednak zajrzeć do pudełek i zobaczyć, że jedno z nich zawiera komputer, a w drugim ukrywa się człowiek z ołówkiem i papierem, wybrałoby się przypuszczalnie dla nich zupełnie odmienne zestawy testów. Oczywiście, to bardzo uproszczony przykład, ale dobrze ilustruje jak znajomość sposobu działania programu wpływa na sposób testowania. Celem testowania jest znajdowanie błędów. Celem lokalizacji i usuwania błędów jest ich likwidacja. Te rejony zazębiają się tam, gdzie staramy się błąd wyizolowac i zidentyfikować jego przyczynę. Dowiemy się na ten temat więcej w rozdziale 18-ym „Raportowanie wyników”, ale na razie przyjmijmy uproszczone wytłumaczenie. Tester oprogramowania ma za zadanie zawęzic problem do naprostszego możliwego testu, który wywołuje symptom poszukiwanego błędu. Testując metodami szklanej skrzynki, możemy często nawet zidentyfikować ”podejrzany” fragment kodu. Programista zajmujący się lokalizowaniem i usuwaniem błędu przejmuje pałeczkę w tym właśnie miejscu, ustala dokładnie przyczynę błędu i usiłuje ją usunąć.
Celem testowania jest znajdowanie błędów. Celem lokalizacji i usuwania błędów jest ich likwidacja. Te rejony zazębiają się tam, gdzie staramy się błąd wyizolowac i zidentyfikować jego przyczynę. Dowiemy się na ten temat więcej w rozdziale 18-ym „Raportowanie wyników”, ale na razie przyjmijmy uproszczone wytłumaczenie. Tester oprogramowania ma za zadanie zawęzic problem do naprostszego możliwego testu, który wywołuje symptom poszukiwanego błędu. Testując metodami szklanej skrzynki, możemy często nawet zidentyfikować ”podejrzany” fragment kodu. Programista zajmujący się lokalizowaniem i usuwaniem błędu przejmuje pałeczkę w tym właśnie miejscu, ustala dokładnie przyczynę błędu i usiłuje ją usunąć. 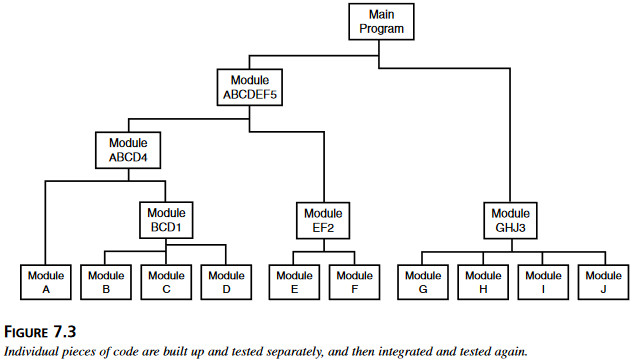 Testowanie na najniższym poziomie nazywane jest testowaniem jednostkowym&testowaniem komponentów albo testowaniem modułu1. Moduły są testowane, błędy w nich znajdowane i usuwane, po czym następuje integracja i test integracyjny grup modułów. Proces przyrostowego testowania przebiega stopniowo, łącząc ze sobą coraz więcej i więcej modułów, aż wreszcie cały produkt – a przynajmniej jego większa część – zostaje przetestowana w całości w ramach testowania systemu.
Testowanie na najniższym poziomie nazywane jest testowaniem jednostkowym&testowaniem komponentów albo testowaniem modułu1. Moduły są testowane, błędy w nich znajdowane i usuwane, po czym następuje integracja i test integracyjny grup modułów. Proces przyrostowego testowania przebiega stopniowo, łącząc ze sobą coraz więcej i więcej modułów, aż wreszcie cały produkt – a przynajmniej jego większa część – zostaje przetestowana w całości w ramach testowania systemu.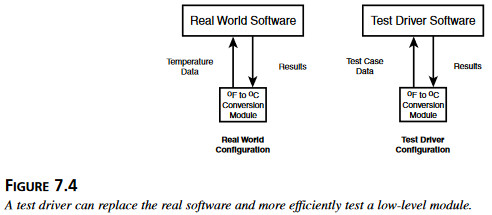

 Specyfikacja funkcji atoi() w języku C. Wydaje się od razu, że ten moduł wygląda jak moduł na najniższym poziomie, taki który jest przywoływany przez inne moduły, ale sam niczego nie przywołuje. Można to ewentualnie potwierdzić, czytając kod modułu. Jeśli tak jest, to logiczną metodą będzie napisanie sterownika testowego, aby móc sprawdzać ten moduł niezależnie od reszty programu.
Specyfikacja funkcji atoi() w języku C. Wydaje się od razu, że ten moduł wygląda jak moduł na najniższym poziomie, taki który jest przywoływany przez inne moduły, ale sam niczego nie przywołuje. Można to ewentualnie potwierdzić, czytając kod modułu. Jeśli tak jest, to logiczną metodą będzie napisanie sterownika testowego, aby móc sprawdzać ten moduł niezależnie od reszty programu.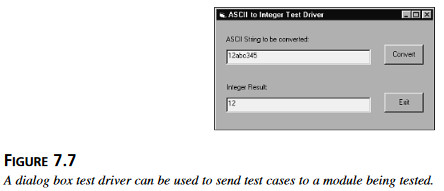 Rysunek 7.7 Sterownik testowy w postaci okna dialogowego może być zastosowany, aby posyłać zadania testowe testowanemu modułowi.
Rysunek 7.7 Sterownik testowy w postaci okna dialogowego może być zastosowany, aby posyłać zadania testowe testowanemu modułowi.

 174.Które zadania testowe są zbędne. Jeśli wykonanie serii zadań testowych nie zwiększa stopnia pokrycia kodu, to przypuszczalnie należą wszystkie one do tej samej klasy równoważności. 175.Jakie nowe zadania testowe trzeba skonstruować aby osiągnąć lepsze pokrycie. Należy zanalizować fragmenty kodu gdzie pokrycie jest słabe, zrozumieć jego działanie i sporządzić nowe zadania testowe, które wykorzystają ten kod.
174.Które zadania testowe są zbędne. Jeśli wykonanie serii zadań testowych nie zwiększa stopnia pokrycia kodu, to przypuszczalnie należą wszystkie one do tej samej klasy równoważności. 175.Jakie nowe zadania testowe trzeba skonstruować aby osiągnąć lepsze pokrycie. Należy zanalizować fragmenty kodu gdzie pokrycie jest słabe, zrozumieć jego działanie i sporządzić nowe zadania testowe, które wykorzystają ten kod.